😐 Nurture a small, healthy, respectful user community. I’m happy that the small circle of existing Origami users seem happy with the system and continue using it. A number of new people tried Origami as well, although most of them fell into the “lurker” category; I have no idea whether they are still using it or, if not, why it didn’t meet their needs. So pragmatically speaking, I didn’t do as well on this goal as I’d hoped. One new Origami site, the documentation for the open-source WESL project, was interesting to me because it uses a GitHub wiki as the content management system.
😃 Make it easier for users to make sites they’re happy with through docs, bug fixes, and features. Most of the work I did this year was driven by user feedback. Some existing users moved additional projects of theirs from other systems to Origami, a good indication of user satisfaction.
The big feature investments I aimed to make in 2025 were:
😃 Language Server Protocol implementation. I wanted to implement an LSP server so that development tools like Microsoft VS Code (and others) could provide code completion and inline error feedback. An LSP is a complex beast, and tackling this goal was a significant undertaking. The LSP is now part of the Origami VS Code extension and published in the VS Code marketplace.
😃 Screencast engine. I wanted a way of introducing new users to Origami through a media somewhere between a video and traditional documentation. A video is insanely time-consuming to produce and can’t be kept up to date; traditional docs are easier to maintain but less interesting to newcomers. I developed a system for creating comics and published an initial introductory comic. I’ve always loved comics and am delighted with how this turned out. I have more plans for the comics system in 2026.
😐 Feature complete for JavaScript expressions. I mostly accomplished what I wanted, which was feature parity with JavaScript expressions, but during the year I moved the goal posts. I ended up investing far more in this area than I’d expected; see below. There are still a few remaining unsupported JavaScript features in Origami that I’m looking forward to implementing.
☹️ Inspector/debugger. My plan was to create a browser-hosted tool that lets a user interactively inspect the call tree of an Origami file so they can more easily diagnose errors and better understand how their code works. I spent a month on this, but it proved to be a bigger job than I’d expected and I ultimately set it aside to pursue other priorities. I plan on trying this again in 2026.
JavaScript with paths
The Origami language has evolved in stages, growing closer and closer to JavaScript, but at the beginning of 2025 there were still distinct differences.
Chief among them was that Origami required the / slash operator as a way of extracting a property from an object. Instead of writing post.title like in JavaScript, you had to write post/title. Origami used a slash to preserve the use of the . period as a valid character in file names like data.json.
Feedback from Origami users indicated that this difference in syntax presented a persistent stumbling block, and I eventually developed a file name heuristic that lets the Origami parser determine whether a . period represents part of a file name or a property access. The parser can handle expressions like data.yaml[0].name and generally do what users expect.
This change was a small but important step forward towards turning Origami into a dialect of JavaScript: “JavaScript with paths”. To that end, other important changes included:
Redefining all builtins as global objects, just like JavaScript, so the old syntax tree:map became the JS-style call Tree.map().
Supporting JavaScript keywords like new. Old syntax: new:@js/Date("2025-12-31") is now new Date("2025-12-31"), just like JavaScript.
Map-based trees
Another significant foundational change this year was in the way Origami represents hierarchical tree-like structures. The higher levels of the Web Origami project rest on a foundational notion of a tree of nodes that may require asynchronous calls to traverse. For the past few years, these trees have been defined by a small proprietary interface, essentially a stripped-down version of the standard JavaScript Map class. Origami didn’t use the Map class itself because it was some quirks.
However, experiments suggested ways to work around those quirks, so I rewrote the foundations of Origami to use Mapas a general interface.
Now most of the tree structures you work with in Origami, including those based on in-memory objects, the file system, and local data like JSON/YAML files, are represented with standard Map instances. Because Map doesn’t support async calls, Origami uses an async variation called AsyncMap to represent network resources.
These architectural changes also necessitated extensive revision of Origami’s documentation, including a completely rewritten pattern walkthrough discussing the use of Map-based trees to represent a wide variety of data sources and operations.
Other additions
Along the way there were many other additions to Origami:
Tree.filter builtin for filtering a tree based on a condition
Tree.mask builtin for filtering a tree based on conditions defined in a second tree
Tree.globKeys builtin to support filtering based on Unix-style glob patterns like *.jpeg
Tree.regExpKeys builtin to support filtering based on JavaScript regular expressions
Origami.mdOutline builtin to extract the tree structure of markdown content, e.g., to generate navigation elements
JavaScript has a Map class for holding key/value pairs, but it’s underused and underappreciated. If you fix the class’ limitations, you can use Map as a building block to create really interesting things.
Photo: Cun Mo, Unsplash
A quick review of Map
The Map class lets you associate keys with values:
The Map class has a number of advantages over plain objects for storing data, but JavaScript syntax makes it easier to create and work with objects so Map doesn’t get used as often as it should.
Extending Map
Map also has one key advantage over a plain object: Map is a class you can extend, so you can expose any key/value data store as a Map.
For example, we can write a FileMap class that makes the contents of a file system folder available as a Map. This ignores the map’s built-in storage, and instead gets the keys and values from the file system:
Most of the time you work with files in code, you’re just reading a list of files and getting their contents, so something like this is much easier to work with than the full file system API.
Better yet, you can immediately pass this kind of file system Map to any code that understands a Map. That provides a desired separation between data storage and code that works on data.
Limitations to work around
Sadly, the Map class is cumbersome to extend: its standard methods like clear(), entries(), and values() will ignore your get() and keys() methods.
markdown.entries(); // empty array ☹️
For comparison, the Python language provides a Mapping abstract base class that is much more helpful than JavaScript’s Map. When you inherit from Mapping, you only need to define a small set of core methods, and the base class uses your definitions to provide the remaining methods.
To compensate for this and other issues with Map, we can create our own base class that inherits from Map but provides all the expected methods:
exportdefaultclassBetterMapBaseextendsMap {
// Override entries() method to call overridden get() and keys()
*entries() {
for (const key ofthis.keys()) {
const value = this.get(key);
yield [key, value];
}
}
…
}
If we derive our FileMap class from this improved base class, the full set of Map methods work as expected:
Once your data is in Map form, you can manipulate it in interesting ways without having to worry about how the original data is defined. For example, you can transform a map of markdown to a map of HTML.
const html = newHtmlMap(markdown);
html.keys(); // ["post1.html", "post2.html", …]
html.get("post1.html"); // "<p>This is <strong>post 1</strong>.</p>\n"
Transforming the values of data often implies a transformation of the keys, so maps are ideal representations of such operations.
Creating a build system with maps
This Map approach is a pattern you can explore in more detail. Because it’s a pattern, you can use it without taking on any new dependencies.
But you can take advantage of the Web Origami project’s async-tree library, which includes:
A better Map base class along these lines, called SyncMap
An asynchronous variant called AsyncMap that can represent network data sources
A more complete FileMap class that supports write operations
You can use this library to construct things like a build system for generating the static files for a site. A sample blog project uses the library to represent the various stages of the build process as Map-based trees:
1. Content tree → 2. Site tree → 3. Build tree
The source content in the file system is represented as a tree of Map objects.
These are transformed with map-based operations and composed into the desired tree of site resources.
The site tree is copied directly into a Map-based representation of the folder that will hold the build output.
The entire build.js build process is very concise and boils down to a copy operation:
import { FileMap, Tree } from"@weborigami/async-tree";
import site from"./site.js";
// Build process writes the site resources to the build folderconst buildTree = newFileMap(newURL("../build", import.meta.url).pathname);
awaitTree.clear(buildTree); // Erase any existing filesawaitTree.assign(buildTree, site); // Copy site to build folder
By using Map as the fundamental building block, this sample project generates the site’s static files using only two dependencies, the async-tree library and a markdown processor.
The AsyncMap variant lets you represent a network data source as an object that has the same methods as a Map but the methods are asynchronous. This lets you pull content from sources like Dropbox or Google Drive using a much simpler API, so you can incorporate content directly from the network into your build process.
The occasion was reading about improvements in async features in today’s release of Python 3.14, which prompted me to write some Python code for the first time in a long while.
The sample blog doesn’t actually need to make async network requests, so it ended up only using sync functions — but all those sync functions are still lazy and do work only when necessary. And with the improvements in Python 3.14, it might be possible to create an AsyncMapping abstract base class as a variation of Mapping to handle the sorts of async network operations that Origami can do, e.g., reading post content directly out of Dropbox or Google Drive.
Creating a static site
Python’s audience has always included people who don’t think of themselves primarily as programmers. That aligns with what I’m trying to do in Origami, so it’s interesting to explore using Python as a possible substrate for Origami ideas.
I’m not familiar with Python static site generators, but they seem to generally take the same framework approach as their Node.js counterparts: impose a particular folder structure, provide a magic transformation of that structure to static files, and offer a degree of customization through configuration.
Like all the blog implementations in this series, this Python project rejects that approach entirely. Instead, the focus is on creating useful functions and abstractions for defining the site you want to create. It leaves you to put the parts together in a way that makes sense to you. You are always in control and can entirely satisfy your requirements.
Lazy maps
Like the JavaScript versions of the sample blog, the Python version attempts to use native language constructions whenever possible. It makes heavy use of Python’s Mapping abstract base class to represent collections which are fundamentally lazy: they do essentially no work when constructed. Only when asked for their keys, or for a particular value for a key, will they do substantive work.
An example of this is the project’s Folder class, which wraps a file system folder as a lazy Mapping (specifically, a MutableMapping, which can be updated after it’s created).
Another example of this are the project’s operations that take one Mapping as input and return a new, transformed Mapping. For example, map_extensions, can convert a virtual collection of .md files into a corresponding collection of .html files.
When backed by a Folder containing post.md, the resulting map-of-a-map says that it contains a post.html – but it hasn’t done the real work for that yet. When you ask for post.html, it will ask the underlying Folder for post.md, translate the markdown content to HTML, then return that result. (The actual data pipeline is slightly more complex; see the ReadMe.)
You can use a debugger to inspect the value of a map like this at runtime with a command like:
list(post_html_docs.items())
This lets you confirm that the map’s keys and values are what you expect.
The beauty of working at this abstract Mapping level is that your code doesn’t need to care how a particular collection is defined – your code can handle real files or generated-on-demand files in exactly the same way.
Defining a site tree with maps
At the project’s highest level, site_tree.py defines the root of the site’s tree of resources as a Mapping. Most of those top-level parts of the sites are also Mapping instances: some like assets and images are real folders; others are virtual collections like posts.
# from src/blog_demo/site_tree.py# The site tree is a tree with Mappings for interior nodes and the desired# resources as leaves. The top level of the tree can invoke functions to# generate the content on demand. Areas which are just Mappings are inherently# lazy and are defined directly.
site_tree = invoke_fns({
"about.html": lambda: about_html(),
"assets": Folder(here / "assets"),
"feed.json": lambda: json.dumps(feed(), indent=2),
"feed.xml": lambda: json_feed_to_rss(feed()),
"images": Folder(here / ".." / ".." / "images"),
"index.html": lambda: pages_area()["1.html"], # same as pages/1.html"pages": lambda: pages_area(),
"posts": posts_area(),
})
This programmatic approach lets you dictate precisely how you want to compose the parts of your site; you’re not trapped within the confines of a framework and someone else’s expectations.
Building and serving
As in Origami, the site’s tree of resources is used in two very different ways.
First, a small web server that accepts any Mapping-based tree converts URL requests like /assets/styles.css into an array of keys ["assets", "styles.css"] that are used to traverse the tree. Given the site_tree.py code above, the first ”assets” key retrieves the Folder wrapper for the real assets folder; the second key retrieves the styles.css file in that folder. Because the site tries to be as lazy as possible, the site only does the work necessary to fulfill the specific request.
Second, building the static site files is simply a matter of copying the site’s virtual tree of resources into a real tree in the file system.
# from src/blog_demo/__main__.pydefbuild(m: Mapping):
"""
Given a mapping representing the site structure, copy the entire tree into
the build folder to create static files.
"""
build_folder = Folder("build")
build_folder.clear()
build_folder.update(m)
A MutableMapping is created for the build output folder; it’s mutable so that files can be written into it.
The site’s tree of resources is copied directly into it using the completely standard update() method to copy one map into another. That boils down the essence of a static site generator to the single line:
build_folder.update(m)
This walks through the source tree m, calling __getitem__ to get each resource. That will trigger the generation of said resource. The result will be passed to the build’ folder’s __setitem__ method to create the corresponding output file.
Assessment
Let’s compare this Python blog port with the earlier Origami and JavaScript versions.
In terms of source code size, the Python version is written as a demo application and a separate library for map manipulations. That makes it roughly comparable to the blog using Origami’s async-tree library. Accordingly, I’ll factor out the library portion of the code, and the reusable JSON feed-to-RSS translation to measure the non-reusable bytes in the demo application, including both Python (.py) files and Jinja (.j2) templates.
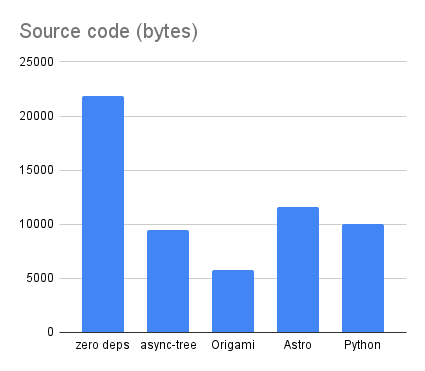
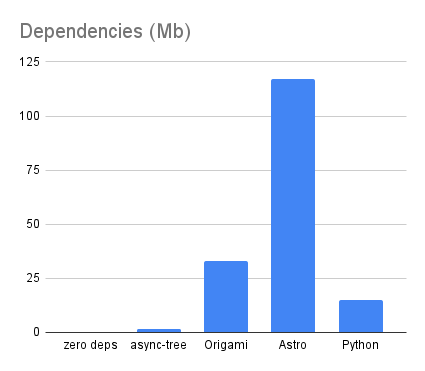
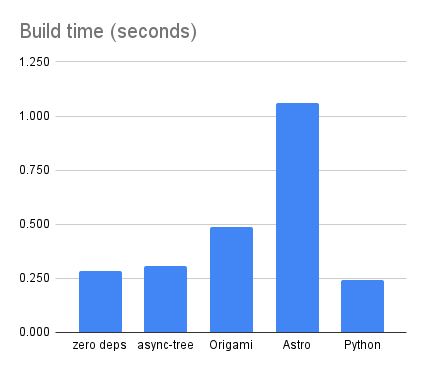
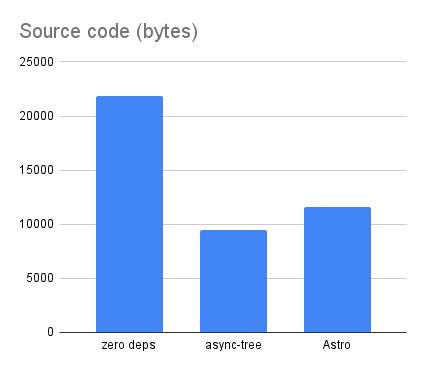
The Python version comes in at 10021 bytes, just a bit more than the 9450 bytes for the async-tree version. For this blog application, at least, both Python and JavaScript are comparably expressive. (Origami is still more concise.)
Python and Node.js are completely different environments, so it’s not possible to make an apples-to-apples comparison of the weight of the project dependencies. And in any case, measuring dependencies by total file size can only give an extremely coarse approximation of potential complexity. Still, I thought it was interesting to measure the total size on disk of the Python project’s site-packages as an analogue for node_modules.
The Python version weighs more than the async-tree version. It’s less than Origami, but Origami is also doing a lot more. (Astro is still the most complex answer to the problem, and I don’t believe it’s actually doing enough interesting work to justify its size.)
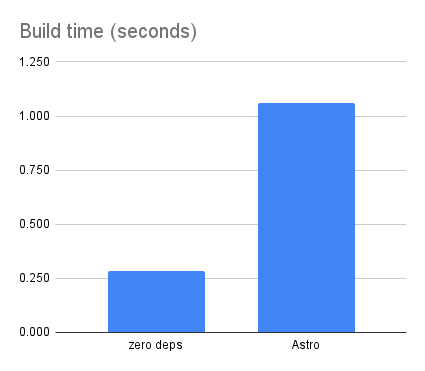
Finally, let’s look at the time required to build the blog’s static files:
Python comes in at 0.24s — a hair faster than the zero-dependency JavaScript version, making it the fastest of all the blog versions I’ve created so far.
Conclusion
This was a really interesting experiment! It was a ton of fun to write Python code again.
It seems completely feasible to serve and build a site in Python in a lightweight fashion using a library (under your control) instead of a big framework (that takes control from you). Python seems like a great substrate for Origami ideas. It’s well-designed and widely-used Mapping abstract base class is a natural way to represent your source content as a tree that you can transform into the tree of resources you want for your site.
Over this summer I’ve shifted the Origami expression language to be a closer dialect of JavaScript expressions. Feedback from early adopters indicated that some differences from JavaScript created trouble; eliminating those would improve the language.
Origami is now essentially JavaScript expressions plus paths, with a few additional syntactic features that make it easier to define a site.
The language supports a conceptual model called Content/Transformation you may find helpful in thinking about how to build a site.
The syntax changes to the language included:
Supporting standard JavaScript . syntax for accessing a property. This required developing a heuristic that could reliably tell that post.title is a property reference but image.jpg is a file name — even though both use the same period syntax.
Consolidating Origami’s built-in functions into a small number of collections exposed as regular globals, like Tree for functions that work with trees and Origami for most everything else.
Supporting JavaScript’s new syntax. I’d tried hard to avoid having reserved words, but new is so ingrained in JavaScript developers’ minds that any other syntax is hard to remember.
Origami is still missing some esoteric JavaScript expression features (e.g., function parameter destructuring), but those are all on the list tackle. The goal is that you should be able to copy any JavaScript expression and evaluate it as an Origami expression.
Why introduce an alternative expression language to JavaScript?
Origami’s use of paths, including support for file extensions and its assumption that any expression might be async, lets you load or fetch files and get data out of them more concisely than with JavaScript. The resulting expression can be 20-40% shorter, making the intent of code easier to see.
Expressions generally don’t have side effects, so restricting your code to expressions tends to keep you in the happy world of pure functions and immutable data — where things are much easier to reason about.
With a few shorthands to accommodate a command line, Origami makes an excellent shell language, turning your OS terminal into a JavaScript console.
Last year I created a sample blog called #pondlife to show how to create a basic blog in Web Origami. Recently I rewrote that same blog three new ways, giving me four implementations to compare:
All four approaches produce the same static blog site — but there are significant differences in how much code each approach entails and how many dependencies they require.
JavaScript isn’t a great fit for making sites
The Origami version is functionally the same as the JavaScript version using the async-tree library. The Origami is able to be more concise by using a dialect of JavaScript expressions. These cut out a fair bit of JavaScript boilerplate so the final source code can focus on the blog I’m trying to create.
The JavaScript language was originally designed for wiring up interactivity on individual pages. It was not designed to create sites, to interact with file system trees or network resources, or to parse and manipulate the contents of files.
Node.js and similar environments do make those things possible in JavaScript — which is great! But the fact remains that JavaScript itself is a poor fit for making sites. Even basic site tasks require you to write quite a bit of JavaScript code.
Example: Generating the About page
As an example, let’s look at the aboutPage.js code in the async-tree version of the blog that reads in a trivial markdown file and transforms it into the simple About page:
import { marked } from"marked";
import fs from"node:fs/promises";
import markdownDocument from"../markdownDocument.js";
import page from"./page.js";
// About page: transforms about.md to HTML and applies the page templateexportdefaultasync () => {
const buffer = await fs.readFile(
newURL("../about.md", import.meta.url).pathname
);
constdocument = awaitmarkdownDocument(buffer);
returnpage({
...document,
// Transform the body to HTMLbody: marked.parse(document.body),
});
};
This gets a reference to the markdown file relative to the JavaScript module, reads in the file buffer, calls a helper to parse that as markdown with front matter, transforms the resulting object to one whose body property is HTML, then passes that to our site’s basic page template to produce the final HTML page.
The above code works but feels verbose for what it’s doing.
Origami is JavaScript expressions plus paths
Many tasks in creating a site or other digital artifact can be handled by an expression — a bit of code that returns a value.
Many web resources can be described as applying one or more functions to some original content or data.
Likewise, converting data to HTML can be described as applying one or more template functions.
The overall structure of a site can be described as a tree, which can be defined by an object literal.
These are all types of expressions.
The Origami language is essentially JavaScript expressions with paths. This is paired with a library of built-in functions to handle tasks that commonly come up when creating sites and other software artifacts. Finally, a command-line interface (CLI) can display the result of an expression or, if the expression produces a complex tree structure, write that result out as a tree of files in the file system.
Expressions are concise
Origami expressions cut down the above code required for things like creating the About page.
Each Origami program file implicitly exports a single expression, so we can drop the export default.
Origami extends the expression’s scope to include the surrounding file system, so we can reference the about.md markdown file by simply writing about.md.
Similarly, instead of statically importing the page.js template, we can refer to page.ori (the corresponding Origami version of the template) by just writing page.ori.
Origami has a system of file type handlers to process data in a file based on its file extension. In this case, Origami’s handler for .md files knows such files contain text and optionally front matter data, so we can drop the need to invoke such code ourselves.
Origami also includes a built-in function mdHtml that can handle the transformation of an object with markdown content into an object with HTML content.
Using file references and built-in functions lets us drop all of the import statements.
Origami assumes that any expression can be potentially asynchronous, so we can drop the async declaration and the await calls.
Instead of assigning interim steps to const variables, the function calls are now so short that we can just collapse them to one calculation.
With all that, we can replace the 17 lines of code shown earlier with a single line:
page.ori(mdHtml(about.md))
This is what I think a language that’s good for making web sites should look like. This line says: “Read in about.md, turn into HTML, and pour that into the base page template.”
It’s great that you can do this in JavaScript too, but compared to the above, JavaScript seems like an awkward fit.
Critically, when you write the above line of code, you are still in control of every step of the process. You can add new operations, change the order of operations, whatever you want.
In contrast, frameworks need to make assumptions about what you want to do. If their assumptions match your needs perfectly, you might not even need to write any code. But as my Astro blog post discussed, if your needs vary even a tiny bit from the framework’s defaults, you may end up writing quite a lot of code.
Distilling the essential site definition
We can make a similar reduction of this site.js code that defines the overall structure of the async-tree blog:
import { FileTree, map, paginate } from"@weborigami/async-tree";
import jsonFeedToRss from"@weborigami/json-feed-to-rss";
import jsonFeed from"./jsonFeed.js";
import posts from"./posts.js";
import aboutPage from"./templates/aboutPage.js";
import multiPostPage from"./templates/multiPostPage.js";
import singlePostPage from"./templates/singlePostPage.js";
// Group posts into pages of 10const pages = map(awaitpaginate(posts, 10), {
extension: "->.html", // Add `.html` to the numeric keysvalue: multiPostPage, // Apply template to the set of 10 posts
});
// Convert posts to a feed object in JSON Feed schemaconst feed = awaitjsonFeed(posts);
//// This is the primary representation of the site as an object. Some properties// are async promises for a single result, others are async trees of promises.//exportdefault {
"about.html": aboutPage(),
assets: newFileTree(newURL("assets", import.meta.url)),
images: newFileTree(newURL("../images", import.meta.url)),
"index.html": pages.get("1.html"), // same as first page in pages area"feed.json": JSON.stringify(feed, null, 2),
"feed.xml": jsonFeedToRss(feed),
pages,
posts: map(posts, singlePostPage),
};
By leaning on Origami’s implicit imports, exports, and async/await support and using the language’s built-in functions, we can reduce the above code to this expression:
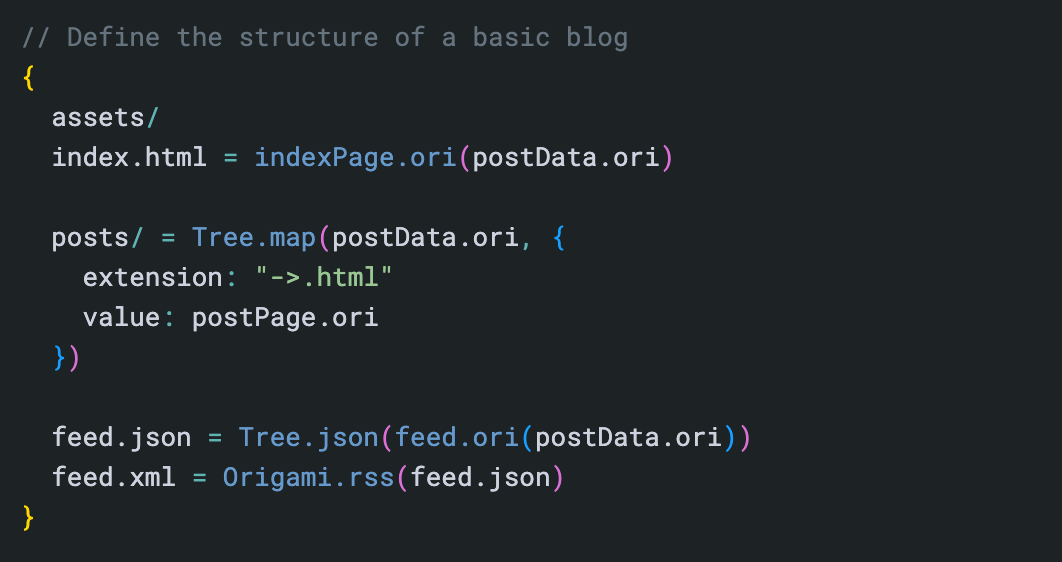
// Define the blog's overall structure
{
// About page uses the basic page templateabout.html=page.ori(mdHtml(about.md))
// Assets (fonts, styles) and images are included as is.assetsimages// Feeds render the posts in JSON Feed and RSS formats
(feed) =feed.ori(posts.ori)
feed.json=json(feed)
feed.xml=rss(feed)
index.html=pages/1.html// same as first page in pages area// Group posts into pages of 10
(paginated) =paginate(posts.ori, 10)
pages/=map(paginated, { extension:"→.html", value:multiPostPage.ori })
// The posts area contains a page for each individual postposts/=map(posts.ori, singlePostPage.ori)
}
The above code is still entirely explicit about declaring the site it produces; Origami is making no assumptions about what you want. The above code is not configuring a blog engine. It’s defining a blog engine from scratch.
I find the Origami version easy enough to read that I can quickly look over a site definition like this — even a definition written by someone else — and quickly apprehend the construction of the entire site.
Assessment
Let’s see how the Origami version compares against the three blog versions discussed earlier.
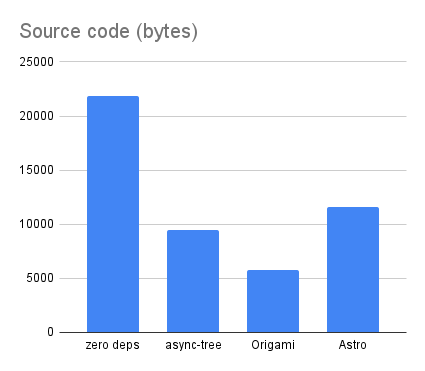
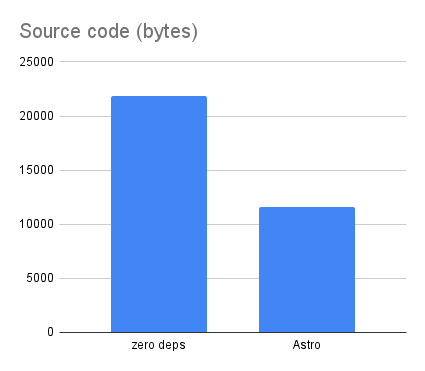
The Origami source code is distinctly smaller than all other forms of the code, coming in at just 5749 bytes:
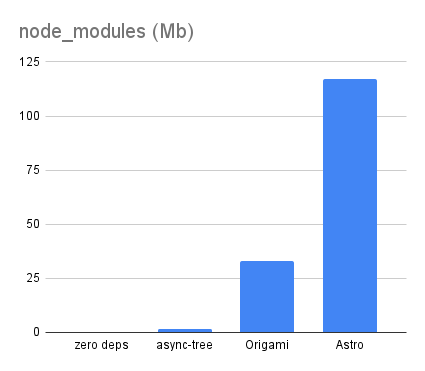
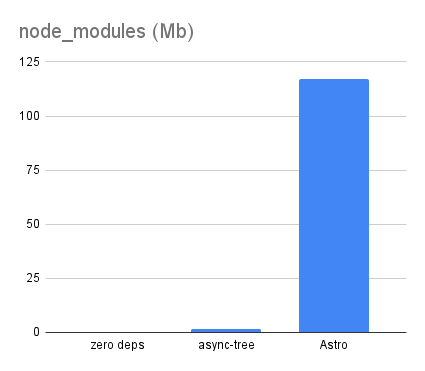
The Origami version using Origami v0.2.12 comes with a non-trivial 33Mb of node_modules, although that’s still less than a third of the 117Mb of node_modules for the Astro version:
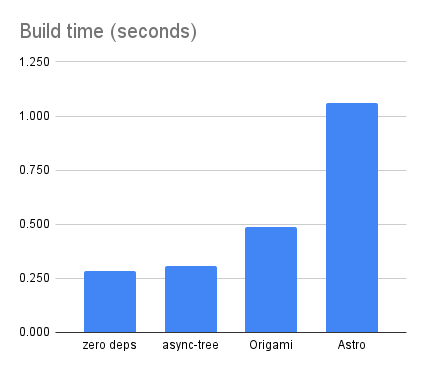
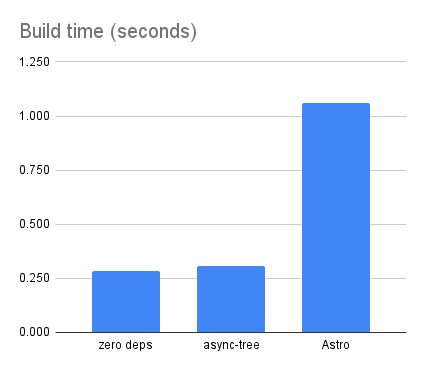
The Origami build time is slightly slower than the zero-dependency and async-tree versions that use only JavaScript. This reflects the cost of the Origami parser and runtime. That said, the Origami version is still faster than Astro for this project:
What do you actually need to learn?
Origami is a dialect of JavaScript expressions. If you don’t already know JavaScript, you’ll need to learn some basics to be productive in Origami. If you do know JavaScript, you need to be aware of the set of JavaScript features supported in Origami and some syntax differences.
Learning a new language dialect does represent some real mental work for you. But Astro and most of the other popular SSG frameworks often impose new language dialects too. In Astro’s case, you need to learn a dialect of JSX, which itself is a dialect of JavaScript and a dialect of HTML.
If you don’t want to learn a new language, I think the async-tree version of the blog is quite nice. An experienced JavaScript developer can take advantage of it without needing to learn a new language at all.
Conclusion
All these projects produce the same site and, depending on who you are and what your goals are, any of them might be appropriate for you.
I myself prefer solutions that are more explicit and less magic. It’s generally a good idea to work as close to the platform as possible; both of the JavaScript versions discussed here have their merits. That said, Origami is so concise and flexible that I can be extremely productive in it and it’s fun to use. I generally prefer it for making sites these days.
Using the async-tree library substantially cuts down the source code for a minimalist static site generator (SSG) in JavaScript, at a very modest cost in dependencies. The result is still fast and flexible.
The zero-dependency version felt quite good, although insisting on no dependencies was a little extreme.
While half the source code was unique to the project, the features in the other half can be cleanly handled by libraries, like:
Transforming markdown to HTML. Markdown processing can be expressed as a pure function that accepts markdown and returns HTML. A processor like marked fits the bill.
These are both pure functions, a much easier kind of dependency to take on. You decide when to call the function and what input to give it; it gives you back a result without any side effects. This contract greatly reduces the potential for surprise or frustration.
The async-tree library
The remaining sharable code in the zero-dependency version comprises generic utility functions:
A higher-order function that maps the keys and values of an object to return a new, transformed object
A way to read and write a file system folder tree as an object
Since these are completely generic, they’re worth sharing — so over the past 4 years I’ve been working on a library called async-tree that handles these and other tasks.
The async-tree library builds on the idea that most of the hierarchical structures we work with can be abstracted to asynchronous trees. When creating a site, we rarely care about how data is stored; we just want to render it into static resources like HTML.
Our collection of markdown documents, for example, is physically stored in the file system — but that’s irrelevant to our static site generator. All we care about are the keys (the file names) and the values (the markdown text with front matter). We can think about this collection of markdown documents as an abstract tree that could be anywhere in memory, on disk, or in the cloud:
If all we want to do is traverse this tree, APIs like Node’s fs API are overkill. We just want a way of getting keys and values. This is much closer in spirit to a JavaScript Map. Unlike Map, we can handle more cases by making our methods async.
This is an interface (not a class) that’s easy to define for any almost any collection-like data structure. Such async collections can be nested to form an async tree — a tree of promises.
Abstractions come a cost. In exchange for a considerable degree of power and flexibility, you have to wrap your brain around an unfamiliar concept. “A tree of promises?” It might take a while to wrap your head around that.
I will say that, from several years of experience, it’s ultimately very beneficial to view software problems like static site generation as reading, transforming, and writing async trees.
Example: reading markdown, reading posts
As an example, to get the first file from our markdown folder, we can construct an AsyncTree for that folder using the library’s FileTree helper, then call the tree’s get method:
Here FileTree is roughly similar to our quick-and-dirty zero-dependency code that read a folder tree into memory. But FileTree is more efficient because it doesn’t read the complete set of files into memory; it only does work when you look up a key’s value with get.
Our posts.js function turns that collection of markdown file buffers into a completely different form: a set of plain JavaScript objects with .html names that are stored in memory. Despite these significant differences, if we want to get the first post from that collection, we can still use the same get method:
import posts from"./src/posts.js";
const first = await posts.get("2025-07-04.html");
Totally different data structure, same get method.
Example: pagination
Another reason to work with collections as abstract trees is that a consistent set of operations can be defined for them regardless of their underlying storage representations.
For example, the zero-dependency version includes a one-off paginate helper that accepts a collection of posts and returns an array grouping the posts into sets of 10. The paginated posts can then be mapped to HTML pages using the project’s own mapObject helper function.
// Group posts into pages of 10const pages = mapObject(paginate(posts, 10), (paginated, index) => [
`${parseInt(index) + 1}.html`, // Change names to `1.html`, `2.html`, ...multiPostPage(paginated), // Apply template to the set of 10 posts
]);
The async-tree library offers the same functionality as a general paginate function which can be applied to a tree defined by any means, including our set of posts. The paginated results can then be turned into HTML with another generic tree operation, map.
// Group posts into pages of 10const pages = map(awaitpaginate(posts, 10), {
extension: "->.html", // Add `.html` to the numeric keysvalue: multiPostPage, // Apply template to the set of 10 posts
});
Mapping the values of a collection often implies changing the file extension on the corresponding keys, so the map function includes an extension option to easily add, change, or remove extensions.
Site definition
As with the zero-dependency version, the async-tree version of the blog defines the overall structure of the site in extremely concise fashion in site.js:
// Group posts into pages of 10const pages = map(awaitpaginate(posts, 10), {
extension: "->.html", // Add `.html` to the numeric keysvalue: multiPostPage, // Apply template to the set of 10 posts
});
// Convert posts to a feed object in JSON Feed schemaconst feed = awaitjsonFeed(posts);
//// This is the primary representation of the site as an object. Some properties// are async promises for a single result, others are async trees of promises.//exportdefault {
"about.html": aboutPage(),
assets: newFileTree(newURL("assets", import.meta.url)),
images: newFileTree(newURL("../images", import.meta.url)),
"index.html": pages.get("1.html"), // same as first page in pages area"feed.json": JSON.stringify(feed, null, 2),
"feed.xml": jsonFeedToRss(feed),
pages,
posts: map(posts, singlePostPage),
};
That’s the whole site. This is the most concise way I know to define a site in JavaScript.
I find this kind of concise overview invaluable when I return to a project after a long break, and a quick glance refreshes my understanding of the site’s structure.
Build
Once the site is defined, building the site is just a matter of copying files from the virtual world to the real world. Here’s the whole build.js script:
import { FileTree, Tree } from"@weborigami/async-tree";
import site from"./site.js";
// Build process writes the site resources to the build folderconst buildTree = newFileTree(newURL("../build", import.meta.url).pathname);
awaitTree.clear(buildTree); // Erase any existing filesawaitTree.assign(buildTree, site); // Copy site to build folder
The async-tree library provides a set of helpers in a static class called Tree. These provide a full set of operations like those in the JavaScript Map class so that AsyncTree interface implementors don’t have to define those methods themselves, making it easier to create new AsyncTree implementations to read data directly out of new data sources.
Assessment
We can compare this async-tree version of the blog with the earlier Astro and zero-dependency versions. All three versions create the same site.
The async-tree version makes strategic use of libraries for markdown processing, RSS feed generation, and manipulating objects and files as trees. This removes over half the code from the zero-dependency version, so async-tree has only 9K handwritten source code, the smallest of the three:
This comes at a modest cost of 1.5Mb of node_modules, or about 1% of the 117Mb of node_modules for the Astro version:
The async-tree version is still extremely fast, just a hair slower than the zero-dependency version:
Nice!
Impressions
Like the zero-dependency version, this async-tree version was fun to write.
The introduction of a limited set of dependencies to this project felt fine. The small libraries I’m using here all do their work as pure functions, so I’m still in control over what’s going on. I don’t have to wrestle with plugins, lifecycle methods, or complex configuration like I would have to in a mainstream SSG framework. I’m just calling functions!
Debugging async JavaScript code is harder than debugging regular, synchronous code. The debugger I use in VS Code does a fairly good job of it, but it’s still not possible to inspect the value of variables across async stack frames. That can make it harder to figure out what’s gone wrong at a breakpoint.
That said, I once again made good use of the ori CLI to check various pieces of the site in the command line. That let me confirm that individual pieces worked as expected, as well as serve the site locally to inspect the evolving site.
All in all, I think this async-tree approach is a really interesting way to build sites. It’s significantly less JavaScript than the zero-dependency version, while it’s still very fast and light on package weight. You stay in control.
Since I wrote the async-tree library, I can’t provide an objective assessment of how difficult it is to use.
The library deserves more comprehensive documentation than it currently has; I’ve generally focused my documentation writing on the higher-level Origami language and its set of builtins. If you’re intrigued by this more foundational, general-purpose async-tree library, let me know. I can help you out and prioritize documenting it in more detail.
Improvable?
As small and focused as the source for this async-tree version is, it can be made even smaller! Next time I’ll revisit the original sample blog that started this post series and show the benefits of writing it in Origami.
Configuring a complex tool can take more work that just coding the functionality you want from scratch. In the last post I described creating a simple blog in Astro, a popular static site generator (SSG). The Astro solution felt more complicated than the problem justified, so I rewrote the entire blog project from scratch in pure JavaScript with zero dependencies.
This went very well! I coded the blog in about a day, I can completely understand every part of it, and it’s very fast. Writing from scratch made it easy to achieve all of the requirements for the site (described in the appendix of the linked post above).
This isn’t a product but a pattern. If you’re familiar with JavaScript, there are only two small ideas here you might not have tried before. I think you’ll find it easier than you expect. I used JavaScript but you could just as easily do this in Python or any other language.
A static site generator reads in a tree of files representing the source content you create by hand and transforms it into a new tree of files representing the static files you deploy. That’s the core of what an SSG does.
To that end, an SSG also helps you with a variety of conventions about how the content is written or what form the resulting static files should take. For a blog, those conventions include:
Letting you write posts in markdown with hardcoded and calculated metadata
Converting markdown to HTML
Applying templates to data and HTML fragments to create a consistent set of final pages
Generating feeds in formats like RSS
Handling one-off markdown pages like the About page
Linking pages together
Individually, each of those transformations is straightforward.
To write this SSG from scratch, we’ll need a way to represent a site overall, a way to read and write content, and a way to specify all those small transformations.
Plain objects and functions are all you need
A useful general principle in coding is to see how far you can get with plain objects and functions. (What JavaScript calls plain objects, Python calls dictionaries and other languages might call associative arrays.) When possible, functions should be pure — that is, have no side effects.
Applying this principle to writing a static site generator:
Read the folders of markdown posts and static assets into plain objects.
Use a sequence of pure functions to transform the posts object into new objects that are closer and closer to the form we want.
Create additional objects for paginated posts, the feeds, and the About page.
Put everything together into a single object representing the site’s entire tree of resources.
Write the site object out to the build folder.
Idea 1: Treat a file tree as an object
Both a tree of files and a plain object are hierarchical, so we can use a plain object to represent a complete set of files in memory. The keys of the object will be the file names, and the values will be the contents of the files. For very large sites keeping everything in memory could an issue, but at the scale of a personal blog it’s generally fine.
If you’ve ever worked with Node’s fs file system API, then recursively reading a tree of files into an object is not a difficult task. The same goes for writing a plain object out to the file system. If you aren’t familiar with fs but are comfortable using AI, this is the sort of code that AI is generally very good at writing.
You can read my handwritten solution at files.js. You could just copy that.
Idea 2: Map objects
Once we have a bunch of files represented as a plain object, we next want some way to easily create new objects in which the files have been transformed.
The JavaScript Array class has a workhorse map function that lets you concisely apply a function to every item an array. Sadly the JavaScript Object class is missing a corresponding function to map the keys and values of an object — but we can create an object-mapping function ourselves:
// Create a new object by applying a function to each [key, value] pairexportfunctionmapObject(object, fn) {
// Get the object's [key, value] pairsconst entries = Object.entries(object);
// Map each entry to a new [key, value] pairconst mappedEntries = entries.map(([key, value]) =>fn(value, key, object));
// Create a new object from the mapped entriesreturnObject.fromEntries(mappedEntries);
}
This little helper forms the core of our transformation work. Since we’re treating a set of files as an object, we can use this helper to transform a set of one kind of file to a set of a different kind of file, renaming the files as necessary.
We will also often want to map just the values of an object while keeping the keys the same, so a related mapValues helper handles that common case.
Preparing the data for rendering
I find it useful to consolidate the work required to read in a site’s source content and prepare it for rendering in a single module. This does all the calculations and transformations necessary to get the content in a form that can be easily rendered to HTML, feeds, and other forms.
This project does that work in posts.js, which exports a plain object with all the posts data ready for render. We can call that a module a “pipeline”; it’s just a series of function calls.
The pipeline starts by using our files helper to read in all the posts in the /markdown folder into an object. The object’s keys are the file names; the values are Buffer objects containing the file’s contents. If we were to render the in-memory object in YAML it would look like:
We now begin a series of transformations using the aforementioned mapObject and mapValues helpers. The first transformation interprets the Buffer as markdown text with a title and body properties. This step also parses the date property from the file name and adds that. The result is that our collection of posts now looks like:
The next step is to turn the markdown in the body properties to HTML. Since the data type is now changing, we can reflect that by changing the file extensions from .md to .html. Result:
We’d like the page for an individual post to have links to the pages for the next and previous posts, so the next step calls a helper to add nextKey and previousKey properties to the post data:
Because the original markdown files have names that start with a date in YYYY-MM-DD format, by default the posts will be in chronological order. We’d like to display the posts in reverse chronological order, so the final step of the pipeline reverses the orders of entries in the top-level object. The posts that were at the beginning will now be at the end of the data:
This is the form of the final object exported by posts.js. It contains all the data necessary to render the posts in various formats.
These steps could all be merged into a single pass but, to me, doing the transformations in separate steps makes this easier to reason about, inspect, and debug. It also means that transformations like adding next/previous links are independent and can be repurposed for other projects.
Template literals are great, actually
Most static site generators come with one or more template languages. For example, here’s the PostFragment.astro template from the Astro version of this blog. It converts a blog post to an HTML fragment:
---
// A single blog post, on its own or in a list
const { post } = Astro.props;
---
<section>
<a href={`/posts/${post.slug}`}>
<h2>{post.frontmatter.title}</h2>
</a>
{
post.date.toLocaleDateString("en-US", {
year: "numeric",
month: "long",
day: "numeric",
})
}
<post.Content />
</section>
This isn’t that bad, although it’s an odd combination of embedded JavaScript and quasi-HTML.
If you’re a JavaScript programmer, you can just use standard JavaScript with template literals to do the exact same thing. Here’s the equivalent postFragment.js function from the zero dependency version:
// A single blog post, on its own or in a listexportdefault (post, key) => `
<section>
<a href="/posts/${key}">
<h2>${post.title}</h2>
</a>
${post.date.toLocaleDateString("en-US", {
year: "numeric",
month: "long",
day: "numeric",
})}${post.body}
</section>
`;
It’s a matter of taste, but I think the plain JS version is as easy to read. It’s also 100% standard, requires no build step, and will work in any JavaScript environment. Best of all, any intermediate or better JavaScript programmer can read and understand it — including future me!
Another wonderful benefit of using simple functions for templates is that they’re directly composable. We can easily invoke the above postFragment.js template in the singlePostPage.js template using regular function call syntax.
We can also use higher-order functions like our mapObject and mapValues helpers to apply templates in the final site.js step discussed later. There we can apply the singlePostPage.js template to every post in the blog with a one-liner:
mapValues(posts, singlePostPage);
Zero dependencies
I challenged myself to create this site with zero dependencies but there were two places where I really wanted help:
Converting markdown to HTML. I’d always taken for granted that one needed to use a markdown processor so I wasn’t sure what I’d do here. Most processors have a ton of options, a plugin model, etc., so they certainly feel like big tools. But at its core, the markdown format is actually straightforward by design. I found the minimalist “drawdown” processor that does the markdown-to-HTML transformation in a single file through repeated regular expression and string replacements. I copied that and ported it to modern ES modules and syntax.
Rendering a JSON Feed object as RSS. This is mostly just string concatenation but I didn’t want to rewrite it by hand. I copied in an existing JSON Feed to RSS module I’d written previously.
If I weren’t pushing myself to hit zero dependencies, I would just depend on those projects. But both of them are small; using local copies of them doesn’t feel crazy to me.
Assembling the complete site as an object
In site.js we combine all the site’s resources into a single large object:
//// This is the primary representation of the site as an object//exportdefault {
"about.html": awaitmarkdownFileToHtmlPage(relativePath("about.md")),
assets: await files.read(relativePath("assets")),
"feed.json": JSON.stringify(feed, null, 2),
"feed.xml": jsonFeedToRss(feed),
images: await files.read(relativePath("../images")),
"index.html": pages["1.html"], // same as first page in pages area
pages,
posts: mapValues(posts, singlePostPage),
};
This takes each of the individual pieces of the site, like the About page, or the RSS feed, or the posts area, and combines them into a single object. That’s our whole site, defined in one place.
A tool to work with the site in the command line
Because everything in this project is just regular objects and functions, it was easy to debug. But I also made ample use of a useful tool: although this site isn’t depending on Origami, I could still use the Origami ori CLI to inspect and debug individual components from the command line.
For example, to dump the entire posts object to the command line I can write the following. (If ori isn’t globally installed, one could do npx ori instead.)
$ ori src/posts.js/
I can do this inside of a VS Code JavaScript Debug Terminal and set breakpoints too. This lets me quickly verify that individual pieces produce the expected output without having to build the whole site.
For example, while working on generating the JSON Feed, I could display just that one resource on demand:
$ ori src/site.js/feed.json
And although my intention was to build a static site, any time I wanted to check how the pages looked in the browser, I could use ori to serve the plain JavaScript object locally:
$ ori serve src/site.js
Origami happily serves and works with plain JavaScript objects, so I could use it without taking on an Origami dependency – the plain JS code that creates the site object doesn’t have to know anything about the tool being used to inspect it.
You could do the same thing, or not — whatever works for you. But using simple data representations does open up the possibility of using general-purpose tools, another reason to do things in the plainest fashion possible.
Building the static files
With all the groundwork laid above, the build process defined in build.js is trivial:
Erase the existing contents of the /build folder.
Load the big object from site.js that represents the entire site.
Write the big object to the /build folder.
That’s it.
Note that, although this project has a “build”, that’s building the site — the project does not have a traditional “build” step that compiles the code (using TypeScript, JSX, etc.) to generate the site. If you wanted that, you could certainly do that; I don’t find it necessary.
Impressions
This was pretty fun.
It was easy to keep the entire process in my head, so I made steady progress the whole time. I don’t think I hit a single real roadblock or had to backtrack.
Of course there were little bugs, but because I was working with plain objects and functions, the bugs were easy to locate, diagnose, and fix.
There were a very few cases where I had to look up anything. In checking the Node.js docs, I did learn about the fs.rm() function, a call I’d somehow overlooked before which removes both files and folders. I’ll now be able to apply that new knowledge in future projects instead of having invested in a niche API I might never use again.
Since I was in complete control over the program, there was no point where I had to struggle with someone else’s opinion.
This took a day’s worth of work. That was distinctly less time (half?) than it took me to write the same blog in Astro. (I’m not knocking Astro; learning any other SSG might have taken just as long.)
The bottom line is that it took me less time to write my own SSG from scratch than it did to learn, configure, and cajole someone else’s SSG into making the same blog.
I think more people who assume they need an SSG should give at least a little consideration to writing it themselves along these lines.
Big frameworks are overkill
As a simple metric, we can look at the size of the source code I wrote in both versions. We have 22K of .js files for the zero-dependency version, and 11K of .js and .astro files for the Astro version:
Most of the lines of code in the Astro version can be directly mapped to a corresponding line of code in the zero-dependency version; they do the same things. The extra 11K in the zero-dependency version are what implements a bespoke static site generator from scratch. (That includes 4K for an entire markdown processor.)
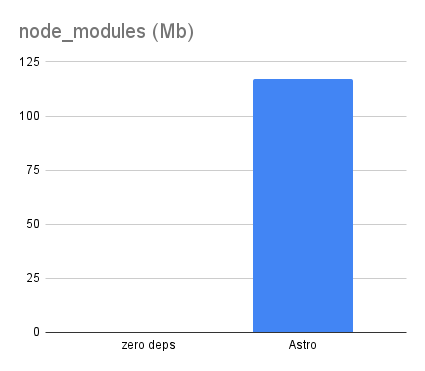
Now let’s compare the size of the node_modules folder for these projects. The zero-dependency version has, by definition, zero, while the Astro version has 117Mb of node_modules.
Both projects produce identical output. The extra 11K of handwritten JavaScript in the zero-dependency version is, for the purposes of this project, functionally equivalent to the subset of the 117Mb Astro actually being used by the Astro version. Those sizes can’t be compared directly, but we’re looking at four orders of magnitude of difference in size.
What is all that Astro code doing? Astro surely has tons of features that are important to somebody — maybe you! But those features are not important to this project. Maybe they’re not important to yours, either.
The complexity in Astro does have some impact on performance. I timed some builds via time npm run build on a 2024 MacBook Air M3. The first build was always the slowest, so I threw that time away and averaged the real time of the next three builds.
I expect the zero dependency version could be made faster, but this already looks pretty good; it’s hard to compete with plain JavaScript and zero dependencies. It’s entirely possible that Astro performs better for larger sites; recall that the zero-dependency version naively loads everything into memory, so at some point that limitation would need to be addressed. At this scale, either approach is fine, but Astro is measurably slower. Note: a 1-second build time is still good!
The point is: I think big SSG frameworks like Astro have a role to play but get used in many situations where something much simpler would suffice or may be superior.
Why not build every site this way?
Although this project didn’t require a lot of code, that 11K of extra JavaScript is generic and could be reused. It’d be reasonable to put those into a library so that similar projects could build with those pieces.
While a library may run into some of the same abstraction issues and potential for bloat as an SSG framework, a library has the critical advantage that it always leaves you in control of the action. Since a good library will do nothing unless you ask for it, in my experience it’s easier to get the results you want.
So having now written this blog three times (Origami, Astro, and plain JS with zero dependencies), I figured I may as well write it a fourth time using a library. I’ll look at that next time.
This minimalist static site generator pattern is only for JavaScript developers who want something small, fast, flexible, and comprehensible [this post]
I took my best shot at recreating a small blog in Astro, a popular static site generator (SSG), so I could compare it with Web Origami and other ways to build a blog.
Results:
I was able to port the blog to Astro, although the port took the better part of two days. This was my first Astro project, but it was more work than I’d expected.
Astro imposed some constraints that forced me to deviate from how I wanted to make my site.
Like many SSGs, Astro covers up parts of the web and Node.js with proprietary languages and abstractions. I find Astro’s replacements more complex than the foundation it covers up.
I came away from the experience with a sense of why people like Astro — but also a feeling that most SSGs are overpowered for the problems most bloggers are trying to solve.
First, though: I love that people love Astro! Anything that makes people more likely to create a site is fantastic. If you’re an Astro fan, you’re all set.
But if you’re shopping for a way to make a site and have heard that Astro (or any other popular site generator) is “simple”, here’s a different opinion. Note: Astro can be used for a variety of purposes, including dynamic sites, but for this project I used Astro exclusively as a static site generator.
My goal was to port my existing sample #pondlife blog to Astro. This blog reimagines Henry David Thoreau as a modern off-the-grid lifestyle influencer. The site is simple but representative of how a small personal blog might start.
Using the original blog as a reference, I had a set of requirements for how the blog should be set up; see the Appendix. I was able to get Astro to meet most but not all of my requirements.
Given that people had described Astro as simple, I was surprised how heavy it felt.
I started with an empty project, rather than cloning a template project, so that I could understand every step. A clean install of Astro includes 100MB of node_modules.
To define the core /posts area, I created a folder structure generally following Astro guidelines, including a /src/posts/[slug].astro file that would do the work of rendering pages in that area. Using the file system in this way to sketch out the site seems reasonable and works fine.
That [slug] file name hints at magic that will turn a request for a page route into a runtime parameter that can be referenced by your code. That’s okay, I guess, although I generally prefer explicit control over magic.
One nit I had about Astro’s build process is that by default it produces noisy console output and I couldn’t find a way to just get errors. It’s a minor point, but it made the tool feel like it was prouder of itself than I thought it deserved.
Neither HTML nor JSX
The body of the [slug].astro page defined the markup for a post:
This markup looks roughly like HTML but it’s not, it’s JSX — or, wait, it’s actually Astro’s own JSX-inspired template language. Many SSGs supply a template language; I wasn’t thrilled at having to learn a new one.
Porting the blog’s original templates to Astro template language wasn’t too much work, but as with JSX I kept getting tripped up by things in Astro that don’t work like real HTML. Case in point: JSX and Astro don’t want you to put quotes around an attribute value in cases like this:
<a href={post.slug}>
My HTML brain really wants to put quotes around that attribute value, because I keep thinking of this as a JavaScript template literal where data is inserted inside ${ } placeholders as is. Astro’s { } placeholders are tricksier than that, with some knowledge of what data is being rendered and when quotes are required.
That’s just me. Perhaps you already understand JSX and will love Astro markup.
Something that looks standard but isn’t
I’d thought of [slug].astro as a page for an individual post — but it’s also where you must write a getStaticPaths() function to tell Astro about your collection of posts. It took some trial and error for me to write that function so Astro could process all the posts in the /markdown folder.
Astro promotes a way of reading in a bunch of files via a method called import.meta.glob. That looks like a part of the web platform but it’s not — I think Astro’s underlying Vite server is hacking that in?
That hackery feels like the JavaScript global-hacking common in the late 2000s and early 2010s that the world eventually realized was a terrible idea and abandoned.
You might think you can go to the import.meta documentation to understand what .glob does. Nope, this is bespoke.
Imagine this .glob idea became wildly successful and someday we wanted to make it part of the actual web. History shows the standard version of the proprietary idea will be different and not backward-compatible — so the standard thing will definitely not be called import.meta.glob! Doing that would break all the existing Astro sites. So in trying to make something look standard, Astro/Vite has prevented it from ever becoming the actual standard.
Even if you like this API, you can’t use it anywhere but an Astro (or Vite?) project.
Why did they go with this fake-standard API? I assume this solution was adopted to save something like a line and a half of plain JavaScript code, which to me doesn’t seem worth it at all.
The functionality of import.meta.glob could just as easily been delivered via a regular JavaScript import. This would not only be simpler to understand, it would have allowed the solution to be used in other kinds of projects.
Content collections
Having gone through the trouble of defining the collection of posts, I was a little surprised I couldn’t find some easy way to refer to that collection elsewhere. For example, I needed to included all those posts in the RSS feed (below), but as originally written, my posts collection was only defined for the /posts route. Maybe I’m missing something?
I did eventually discover Astro’s newer content collections feature, which appears less magic and so conceptually cleaner.
That said, content collections are more complex, and I struggled to get them to work. I eventually gave up and factored my functioning import.meta.glob solution into its own file so I could just import that wherever I needed it.
When you say “never”, do you mean…
In the original blog, the posts live at URLs like /posts/slug.html but I could not get Astro to support that.
Instead, Astro really, really wants me to publish posts at /posts/slug/index.html. That URL format is a common and reasonable one — but it’s not the only format, and it’s limiting to enforce that.
I eventually discovered a configuration option trailingSlash: "never" that appeared to give me what I want. While trying Astro’s preferred RSS solution, I also had to set a separate configuration option with a confusingly different syntax, trailingSlash: false.
This was all annoying but par for the course. What was genuinely frustrating is that the trailingSlash: "never" option appears to only affect dynamic routes at runtime. The option is ignored at build time, so I still ended up with post pages like /posts/slug/index.html.
Aside: I’ve deployed this Astro blog on Netlify, which happens to have a pretty URLs feature that treats /posts/slug.html and /posts/slug/index.html as equivalent. So I get what I want with this particularly host, but I don’t like depending on host URL magic, and I don’t like the lack of control.
Complex tools like Astro make decisions for you, which can make it easier to get started but harder to get what you want. Sometimes there are configuration options; sometimes even those won’t do what you want.
Configuration oddity
Speaking of configuration, you configure Astro in an astro.config.js file like this:
What caught my attention here was the special defineConfig() method — why isn’t this file just exporting a JavaScript object?
The Astro Configuration Overview answers: “The defineConfig() helper provides automatic IntelliSense in your IDE.”
So Astro is encouraging me to do something in a proprietary way in order that, for the few minutes I’m typing in the configuration file, the editor can auto-complete the names of options. I’m already looking at the config file docs — how else am I going to really understand what these options do? — so this whole defineConfig() feature feels like it’s solving a problem I don’t have.
I tried dropping the defineConfig() call and just exporting the object, and that actually works! I wish the docs just promoted that instead.
Complying with their opinion
Astro’s Project Structure documentation says: “Astro leverages an opinionated folder layout for your project.” That opinion is part of their value proposition — they’ve worked out what they believe is a good project structure so you don’t have to spend time thinking about it.
That said, when you’re setting up a blog, you have your own reasons for wanting to put files in specific places. For example, if you’re working in an image editor and need to keep specifying an export folder, it’s nice to have the target folder of images be as close to a project’s top level as possible.
In my case, I wanted to be able to keep the post text in a top-level /markdown folder and the corresponding images in a top-level /images folder.
So when Astro said it had opinions about folder layout, I’d assumed I could override that opinion through configuration. Indeed, I was able to write code to load the posts from /markdown.
But Astro forced me to put all the static resources like images inside a /public subfolder like /public/images. I couldn’t find any way to configure around that, which was disappointing.
That’s a great approach! (Nit: that object schema is proprietary. I’d prefer to see the data object constructed following the JSON Feed schema. That supports the same information while also being a useful feed format itself.)
I couldn’t actually get that @astrojs/rss package to work as advertised — it kept trying to decode HTML entities like < in tag names to <. I tried to follow the documentation pattern as closely as possible but was still unable to resolve the problem after searching, reading docs, and reading issues.
After spending over an hour on it, I gave up and just reused a function I’d written elsewhere for generating RSS.
I assume I was just missing something simple here, so I won’t count this as an Astro issue. That said, I was surprised I couldn’t find a solution to a problem pertaining to RSS feeds, a fundamental blog feature.
Plugins
The communities around frameworks like Astro are justifiably proud of the many plugins (or “integrations” in Astro parlance) they build for their favorite tool. It’s encouraging to see so many people solving problems and sharing their solutions to help others.
But we should question the entire premise of a plugin architecture: that you should not be in control of the action. That’s a long topic that will have to wait for another time.
Covering up Node.js
Because I was using Astro with Node.js, I was stunned by this statement in the Astro Imports reference documentation:
We encourage Astro users to avoid Node.js builtins (fs, path, etc.) whenever possible. Astro is compatible with multiple runtimes using adapters. This includes Deno and Cloudflare Workers which do not support Node builtin modules such as fs.
I don’t use Cloudflare Workers so I’ll take Astro’s assertion at face value. But I’d always thought that Deno had a compatibility layer for Node.js. Indeed, Deno explicitly says you can use Node’s built-in modules in Deno. Why would Astro contradict this claim? Are there specific Deno compatibility issues?
I assume there are Astro customers who care a lot about those other runtimes — but surely that’s a minority of their users? Perhaps I’m confused about their core audience.
If I’m using Astro as an SSG to make a basic blog, I don’t care about those other runtimes. And if you are looking at Astro to make a basic blog, then very likely you don’t care about those other runtimes either.
Astro’s vision of abstracting itself on top of multiple platforms imposes a real cost in complexity. It’s also clear that they want you to only use their APIs — which will make it hard for you to migrate away from Astro. And when you eventually create a site in a different system, knowledge of Astro’s proprietary API will be useless to you.
The silly Astro toolbar
When testing my blog, I noticed an odd visual glitch at the bottom of the page:
I thought this clipped black lump was a bug. When I went to inspect it, this appeared:
So this is an Astro toolbar. Most of the “features” in the toolbar are links to Astro documentation and other parts of their site.
I’m really baffled by this.
I already had to find the Astro documentation to get started. Why did Astro think I need more ways to get to the docs? Why would I want to do that from inside my running site?
I’m trying to make a static site with HTML and CSS only. I don’t want any JavaScript anywhere near my site. Get that stuff away from me!
This just looks like an ad — an ad Astro has placed without permission in my own site. It makes it feel like I don’t control my own site. Ick.
The toolbar made me think: Gosh, what other JavaScript is being loaded by this page? Answer: 1.75MB of JS. I was expecting a tiny bit of code to support hot reloading, but that’s huge. If I were writing client-side JavaScript for these pages, that’s 1.75MB of unknown code that can potentially conflict with code I’m writing.
Ironically, the current Why Astro? page specifically says: Zero JS, by default: Less client-side JavaScript to slow your site down.
Yes, the silly toolbar won’t appear in production. Yes, there’s a configuration option that can turn off this silly toolbar in development.
But the damage is done: all this silly toolbar accomplished was to make me deeply suspicious of Astro’s intentions.
Impressions
It took me the better part of two days to port this blog, which felt long. Your mileage may vary.
The things I liked about Astro:
Having Astro give you the confidence to make a site is good
Using the file system for routing is reasonable
Hot module replacement is nice
Astro’s documentation is quite good
Astro’s contributors are clearly committed to quality
Having a large user community is great
The things I didn’t like:
So many things felt unnecessarily complicated
I couldn’t put my static assets where I wanted
I couldn’t use the URL scheme I wanted
I struggled to define my content collection
I struggled to define an RSS feed
Silly toolbar ad thing
My largest issue with Astro and SSGs like it is that I couldn’t easily construct a mental model of how it worked. I was looking for some overall picture that said: “Here’s the step-by-step process of what Astro does when it builds your site…” but could not find that.
That’s a big request! Going through this with Astro made me appreciate the difficulty of going through a similar process with my own project — something I hope to fix.
Is all this complexity necessary?
Although people had told me Astro is simple, I thought it was quite complex for basic sites like blogs.
Stepping back, what work is actually required to statically generate a blog site?
Represent the complete site in a coherent way
Read in a folder of markdown posts with hardcoded and calculated metadata
Convert the markdown to HTML
Apply a template to turn those posts into final pages
Generate feeds like RSS
Handle one-off pages like the About page
Link everything together
Write all the pages out to the file system
Taken individually, none of these tasks is that much work.
The entirety of an SSG might seem daunting, but many programmers would probably feel comfortable doing these individual tasks. And the sum of a small set of doable tasks is a doable task.
To prove that, I want to rewrite this sample blog again, this time in vanilla JavaScript with no dependencies. I predict this will take slightly more code than the Astro version but will be just as functional, more standard, and more comprehensible.
Read the other posts in this series:
Static site generators like Astro are actually pretty complex for the problems they solve [this post]
Taking the original #pondlife blog as a reference for the Astro blog, here were my requirements for the project source code (things that only matter to me as the author):
The blog posts go in a top-level /markdown folder.
Each markdown post has a name containing a date like 2025-07-04.md; this date should be used as the date for the post. Each post has YAML front matter containing a title property. The body of the post is markdown that should be converted to HTML.
The images for the posts go in an /images folder.
The site’s static assets go in /src/assets.
A standard page template is used for all posts to provide consistent headers, footers, etc.
The project output goes in the /build folder.
I couldn’t find a way to meet requirements #3 and #4, but was able to meet the rest of these.
And here were my requirements for the final site (things end users can see):
Posts appear in reverse chronological order.
The site’s /posts area offers direct links to all individual posts, with a URL like /posts/2025-07-04.html.
Posts have links to older/newer posts.
The site’s /pages area offers the posts grouped in sets of 10, e.g., /pages/1.html contains the first 10 posts.
Those grouped pages have links to older/newer pages.
The site’s /index.html home page shows the same content as /pages/1.html.
The blog supports feeds in RSS and JSON Feed formats.
An additional /about.html page offers information about the site using content drawn from a page at /src/about.md.
I had some trouble getting Astro to meet requirements #8 and #10: the server would accept the format I wanted but the build process wouldn’t create pages following that format.
When my kids were young, we did lots of science and engineering things with them to entertain them or just to alleviate boredom. We visited many science museums. We did numerous kits (e.g., Tinker Crate a.k.a KiwiCo), as well as followed published activities like the Marshmallow Challenge or recipes like
homemade ginger ale (which was just okay).
But most of our favorite projects were things we made up.
Make a “bagpipe” out of a recorder, a plastic bag, and a straw. A bagpipe can play a constant note for longer than a human can exhale: the player blows into a bag, then squeezes the bag to force the air through an instrument. You can rig something together that will do the same thing.
Try to figure out how best to keep an ice cube from melting. Do this as little experiments to figure out what helps. E.g., place a control ice cube in a cup and another on a wire mesh suspended over the cup. Which lasts longer? Why? Also: put two ice cubes in cups, then have your kid cover one with their warmest winter jacket. Which will melt first?
Use a protractor and some math to try to measure the height of a tall tree in the neighbor’s yard, then figure out whether it’s close enough to your house to hit it.
Make a wood swing. Our swing still sits in our front yard and is used daily by passing kids.
Create a scale model of the Earth/Moon system. A globe of the Earth has an enormous amount of play and educational value. Somehow we also ended up with a globe of the Moon. (You could also just print pictures out on a paper.) We worked out how far apart they should be at scale, then physically put them that distance apart. It’s further than you think. In our case the straight-line distance just barely fit inside our first floor.
“Potion Lab”: mix household substances together and see what you get. (Our kids generally pursued two lines of research: fragrances and insecticides.) If the substances include baking soda and vinegar, eventually something surprising will happen.
Construct a maze for a hamster.
Create an elevator for stuffed animals.
Create a zipline for stuffed animals.
Weigh all the stuffed animals on a kitchen scale to determine who is the lightest and who is the heaviest.
Gather all the Legos in the house and try to build a freestanding tower that can reach the ceiling. This is a good use for Duplos. Our house has a light well to the second floor, and we were just barely able to make a tower on the first floor that reached up to the level of the second.
Body conductivity. One electronics kit included a tiny speaker alarm powered by AA batteries. Our kids discovered that if their fingers were wet, and they each held a wire leading to the speaker, they could touch each other and the alarm would sound. They found this to be absolutely hilarious.
Get a can of soda or any processed sweet food with an ingredients label. Find out much sugar is in the thing, covert the grams to teaspoons (4 g = 1 tsp), then make a pile of that much sugar. Compare different things to find the thing with the most added sugar, then make that pile of sugar. Consider whether you now want to eat that pile of sugar.
Proprioception challenge: stand a couple of feet away from some cups on the floor. Close your eyes and keep them closed as you try to drop a marble into a cup. (This was part of a longer series of challenges to show that you have way more than five senses.)
Build a big crane that can dangle a cat toy from the second floor to the first floor.
Business/index card “sailboats”. You may be able to do this at a restaurant if the host counter offers business cards and you have a glassy table. Fold a card any way you want, place it on a smooth table, then blow on it. Try to come up with the one that glides the best across the table.
These specific activities were all great fun — but the point is that you can do a lot with what you already have. The main thing is to decide to do something, spot something you can work with, and then announce that it’s time for a project.
Tip: You can make any project more interesting by giving it a distinctive name. You’re not making a crane, you’re making a Sky Crane. You’re not making a cat bed, you’re making The Circle of Comfort. Sometimes the name comes at the beginning; sometimes one of you will say something funny in the middle and you can use that.
The open source WESL (#WebGPU Shading Language) project recently launched a new WESL documentation site. While helping the group create their site, I realized they could pull their markdown content directly from the places they already keep it.
A key question for any documentation project: how and where should the manually-authored content be stored?
The WESL project maintains two collections of markdown content aimed at different audiences:
The WESL wiki has how-to guidance for devs that want to use WESL in WebGPU projects.
The WESL spec is a collection of more formal documents for implementers.
These collections work well just as they already are, so I thought it’d be good to let the documentation site pull content from these sources using git submodules. The spec is a regular git repository, and behind the scenes a GitHub wiki is a git repository too. Submodules introduce complexities and are not for everyone, but here they let the site project access both repos locally as subfolders.
It was easy to write a program in Origami that pulls content from these subfolders, transforms the markdown to HTML, and pours the HTML into a page template.
The Origami site definition added navigation links, including a pop-up navigation menu for small window sizes.
The wiki and spec both link to each other. A small JavaScript function fixes up those links; the Origami program can easily call that for each document.
I was happy to discover that using a standard HTML <details> element with absolute positioning could do the heavy lifting for a reasonable pop-up menu with very little client-side JavaScript.
Adding full-text search to the complete document collection was just a one-liner via the Origami pagefind extension.
Using git submodules means that wiki or spec updates don’t automatically appear on the documentation site; someone has to go into the site project and pull the latest wiki and spec changes. Having a manual step like that might count as an advantage or a disadvantage depending on your situation.
I was really happy with how small the source for this project ended up being. Setting aside the HTML templates, only ~200 lines of Origami and vanilla JavaScript are required to define the entire site and the client-side behavior.
This is tiny. Origami is a general-purpose system for building sites; it’s not specifically a documentation site generator. This small amount of code defines a bespoke documentation system from scratch.
Using a wiki for documentation this way is really interesting! Project contributors can freely edit wiki pages using familiar tools, then have all that content turned into a static documentation site that project users can freely browse.
 Photo: Cun Mo, Unsplash
Photo: Cun Mo, Unsplash