This minimalist static site generator pattern is only for JavaScript developers who want something small, fast, flexible, and comprehensible
Configuring a complex tool can take more work that just coding the functionality you want from scratch. In the last post I described creating a simple blog in Astro, a popular static site generator (SSG). The Astro solution felt more complicated than the problem justified, so I rewrote the entire blog project from scratch in pure JavaScript with zero dependencies.
This went very well! I coded the blog in about a day, I can completely understand every part of it, and it’s very fast. Writing from scratch made it easy to achieve all of the requirements for the site (described in the appendix of the linked post above).
This isn’t a product but a pattern. If you’re familiar with JavaScript, there are only two small ideas here you might not have tried before. I think you’ll find it easier than you expect. I used JavaScript but you could just as easily do this in Python or any other language.
You can look at the final zero-dependencies blog source code and the live site.
What is a static site generator doing?
A static site generator reads in a tree of files representing the source content you create by hand and transforms it into a new tree of files representing the static files you deploy. That’s the core of what an SSG does.
To that end, an SSG also helps you with a variety of conventions about how the content is written or what form the resulting static files should take. For a blog, those conventions include:
- Letting you write posts in markdown with hardcoded and calculated metadata
- Converting markdown to HTML
- Applying templates to data and HTML fragments to create a consistent set of final pages
- Generating feeds in formats like RSS
- Handling one-off markdown pages like the About page
- Linking pages together
Individually, each of those transformations is straightforward.
To write this SSG from scratch, we’ll need a way to represent a site overall, a way to read and write content, and a way to specify all those small transformations.
Plain objects and functions are all you need
A useful general principle in coding is to see how far you can get with plain objects and functions. (What JavaScript calls plain objects, Python calls dictionaries and other languages might call associative arrays.) When possible, functions should be pure — that is, have no side effects.
Applying this principle to writing a static site generator:
- Read the folders of markdown posts and static assets into plain objects.
- Use a sequence of pure functions to transform the posts object into new objects that are closer and closer to the form we want.
- Create additional objects for paginated posts, the feeds, and the About page.
- Put everything together into a single object representing the site’s entire tree of resources.
- Write the site object out to the build folder.
Idea 1: Treat a file tree as an object
Both a tree of files and a plain object are hierarchical, so we can use a plain object to represent a complete set of files in memory. The keys of the object will be the file names, and the values will be the contents of the files. For very large sites keeping everything in memory could an issue, but at the scale of a personal blog it’s generally fine.
If you’ve ever worked with Node’s fs file system API, then recursively reading a tree of files into an object is not a difficult task. The same goes for writing a plain object out to the file system. If you aren’t familiar with fs but are comfortable using AI, this is the sort of code that AI is generally very good at writing.
You can read my handwritten solution at files.js. You could just copy that.
Idea 2: Map objects
Once we have a bunch of files represented as a plain object, we next want some way to easily create new objects in which the files have been transformed.
The JavaScript Array class has a workhorse map function that lets you concisely apply a function to every item an array. Sadly the JavaScript Object class is missing a corresponding function to map the keys and values of an object — but we can create an object-mapping function ourselves:
// Create a new object by applying a function to each [key, value] pair
export function mapObject(object, fn) {
// Get the object's [key, value] pairs
const entries = Object.entries(object);
// Map each entry to a new [key, value] pair
const mappedEntries = entries.map(([key, value]) => fn(value, key, object));
// Create a new object from the mapped entries
return Object.fromEntries(mappedEntries);
}
We can use this helper like so:
import { mapObject } from "./utilities.js";
const object = { a: 1, b: 2, c: 3 };
const mapped = mapObject(object, (value, key) => [
key.toUpperCase(), // Convert key to uppercase
value * 2, // Multiply value by 2
]);
console.log(mapped); // { A: 2, B: 4, C: 6 }
This little helper forms the core of our transformation work. Since we’re treating a set of files as an object, we can use this helper to transform a set of one kind of file to a set of a different kind of file, renaming the files as necessary.
We will also often want to map just the values of an object while keeping the keys the same, so a related mapValues helper handles that common case.
Preparing the data for rendering
I find it useful to consolidate the work required to read in a site’s source content and prepare it for rendering in a single module. This does all the calculations and transformations necessary to get the content in a form that can be easily rendered to HTML, feeds, and other forms.
This project does that work in posts.js, which exports a plain object with all the posts data ready for render. We can call that a module a “pipeline”; it’s just a series of function calls.
The pipeline starts by using our files helper to read in all the posts in the /markdown folder into an object. The object’s keys are the file names; the values are Buffer objects containing the file’s contents. If we were to render the in-memory object in YAML it would look like:
2025-07-04.md: <Buffer data>
2025-07-07.md: <Buffer data>
… more posts …
We now begin a series of transformations using the aforementioned mapObject and mapValues helpers. The first transformation interprets the Buffer as markdown text with a title and body properties. This step also parses the date property from the file name and adds that. The result is that our collection of posts now looks like:
2025-07-04.md:
title: Hello from the pond!
date: 2025-07-04T17:00:00.000Z
body: **Hey everyone!** Welcome to my very first blog post…
2025-07-07.md:
title: Tiny home
date: 2025-07-07T17:00:00.000Z
body: When I first decided to move off-grid…
… more posts …
The next step is to turn the markdown in the body properties to HTML. Since the data type is now changing, we can reflect that by changing the file extensions from .md to .html. Result:
2025-07-04.html:
title: Hello from the pond!
date: 2025-07-04T17:00:00.000Z
body: <strong>Hey everyone!</strong> Welcome to my very first blog post…
2025-07-07.html:
title: Tiny home
date: 2025-07-07T17:00:00.000Z
body: When I first decided to move off-grid…
… more posts …
We’d like the page for an individual post to have links to the pages for the next and previous posts, so the next step calls a helper to add nextKey and previousKey properties to the post data:
2025-07-04.html:
title: Hello from the pond!
date: 2025-07-04T17:00:00.000Z
body: <strong>Hey everyone!</strong> Welcome to my very first blog post…
nextKey: 2025-07-07.html
2025-07-07.html:
title: Tiny home
date: 2025-07-07T17:00:00.000Z
body: When I first decided to move off-grid…
nextKey: 2025-07-10.html
previousKey: 2025-07-04.html
… more posts …
Because the original markdown files have names that start with a date in YYYY-MM-DD format, by default the posts will be in chronological order. We’d like to display the posts in reverse chronological order, so the final step of the pipeline reverses the orders of entries in the top-level object. The posts that were at the beginning will now be at the end of the data:
… more posts …
2025-07-07.html:
title: Tiny home
date: 2025-07-07T17:00:00.000Z
body: When I first decided to move off-grid…
nextKey: 2025-07-10.html
previousKey: 2025-07-04.html
2025-07-04.html:
title: Hello from the pond!
date: 2025-07-04T17:00:00.000Z
body: <strong>Hey everyone!</strong> Welcome to my very first blog post…
nextKey: 2025-07-07.html
This is the form of the final object exported by posts.js. It contains all the data necessary to render the posts in various formats.
These steps could all be merged into a single pass but, to me, doing the transformations in separate steps makes this easier to reason about, inspect, and debug. It also means that transformations like adding next/previous links are independent and can be repurposed for other projects.
Template literals are great, actually
Most static site generators come with one or more template languages. For example, here’s the PostFragment.astro template from the Astro version of this blog. It converts a blog post to an HTML fragment:
---
// A single blog post, on its own or in a list
const { post } = Astro.props;
---
<section>
<a href={`/posts/${post.slug}`}>
<h2>{post.frontmatter.title}</h2>
</a>
{
post.date.toLocaleDateString("en-US", {
year: "numeric",
month: "long",
day: "numeric",
})
}
<post.Content />
</section>
This isn’t that bad, although it’s an odd combination of embedded JavaScript and quasi-HTML.
If you’re a JavaScript programmer, you can just use standard JavaScript with template literals to do the exact same thing. Here’s the equivalent postFragment.js function from the zero dependency version:
// A single blog post, on its own or in a list
export default (post, key) => `
<section>
<a href="/posts/${key}">
<h2>${post.title}</h2>
</a>
${post.date.toLocaleDateString("en-US", {
year: "numeric",
month: "long",
day: "numeric",
})}
${post.body}
</section>
`;
It’s a matter of taste, but I think the plain JS version is as easy to read. It’s also 100% standard, requires no build step, and will work in any JavaScript environment. Best of all, any intermediate or better JavaScript programmer can read and understand it — including future me!
Another wonderful benefit of using simple functions for templates is that they’re directly composable. We can easily invoke the above postFragment.js template in the singlePostPage.js template using regular function call syntax.
We can also use higher-order functions like our mapObject and mapValues helpers to apply templates in the final site.js step discussed later. There we can apply the singlePostPage.js template to every post in the blog with a one-liner:
mapValues(posts, singlePostPage);
Zero dependencies
I challenged myself to create this site with zero dependencies but there were two places where I really wanted help:
- Converting markdown to HTML. I’d always taken for granted that one needed to use a markdown processor so I wasn’t sure what I’d do here. Most processors have a ton of options, a plugin model, etc., so they certainly feel like big tools. But at its core, the markdown format is actually straightforward by design. I found the minimalist “drawdown” processor that does the markdown-to-HTML transformation in a single file through repeated regular expression and string replacements. I copied that and ported it to modern ES modules and syntax.
- Rendering a JSON Feed object as RSS. This is mostly just string concatenation but I didn’t want to rewrite it by hand. I copied in an existing JSON Feed to RSS module I’d written previously.
If I weren’t pushing myself to hit zero dependencies, I would just depend on those projects. But both of them are small; using local copies of them doesn’t feel crazy to me.
Assembling the complete site as an object
In site.js we combine all the site’s resources into a single large object:
//
// This is the primary representation of the site as an object
//
export default {
"about.html": await markdownFileToHtmlPage(relativePath("about.md")),
assets: await files.read(relativePath("assets")),
"feed.json": JSON.stringify(feed, null, 2),
"feed.xml": jsonFeedToRss(feed),
images: await files.read(relativePath("../images")),
"index.html": pages["1.html"], // same as first page in pages area
pages,
posts: mapValues(posts, singlePostPage),
};
This takes each of the individual pieces of the site, like the About page, or the RSS feed, or the posts area, and combines them into a single object. That’s our whole site, defined in one place.
A tool to work with the site in the command line
Because everything in this project is just regular objects and functions, it was easy to debug. But I also made ample use of a useful tool: although this site isn’t depending on Origami, I could still use the Origami ori CLI to inspect and debug individual components from the command line.
For example, to dump the entire posts object to the command line I can write the following. (If ori isn’t globally installed, one could do npx ori instead.)
$ ori src/posts.js/
I can do this inside of a VS Code JavaScript Debug Terminal and set breakpoints too. This lets me quickly verify that individual pieces produce the expected output without having to build the whole site.
For example, while working on generating the JSON Feed, I could display just that one resource on demand:
$ ori src/site.js/feed.json
And although my intention was to build a static site, any time I wanted to check how the pages looked in the browser, I could use ori to serve the plain JavaScript object locally:
$ ori serve src/site.js
Origami happily serves and works with plain JavaScript objects, so I could use it without taking on an Origami dependency – the plain JS code that creates the site object doesn’t have to know anything about the tool being used to inspect it.
You could do the same thing, or not — whatever works for you. But using simple data representations does open up the possibility of using general-purpose tools, another reason to do things in the plainest fashion possible.
Building the static files
With all the groundwork laid above, the build process defined in build.js is trivial:
- Erase the existing contents of the
/buildfolder. - Load the big object from
site.jsthat represents the entire site. - Write the big object to the
/buildfolder.
That’s it.
Note that, although this project has a “build”, that’s building the site — the project does not have a traditional “build” step that compiles the code (using TypeScript, JSX, etc.) to generate the site. If you wanted that, you could certainly do that; I don’t find it necessary.
Impressions
This was pretty fun.
- It was easy to keep the entire process in my head, so I made steady progress the whole time. I don’t think I hit a single real roadblock or had to backtrack.
- Of course there were little bugs, but because I was working with plain objects and functions, the bugs were easy to locate, diagnose, and fix.
- There were a very few cases where I had to look up anything. In checking the Node.js docs, I did learn about the
fs.rm()function, a call I’d somehow overlooked before which removes both files and folders. I’ll now be able to apply that new knowledge in future projects instead of having invested in a niche API I might never use again. - Since I was in complete control over the program, there was no point where I had to struggle with someone else’s opinion.
This took a day’s worth of work. That was distinctly less time (half?) than it took me to write the same blog in Astro. (I’m not knocking Astro; learning any other SSG might have taken just as long.)
The bottom line is that it took me less time to write my own SSG from scratch than it did to learn, configure, and cajole someone else’s SSG into making the same blog.
I think more people who assume they need an SSG should give at least a little consideration to writing it themselves along these lines.
Big frameworks are overkill
As a simple metric, we can look at the size of the source code I wrote in both versions. We have 22K of .js files for the zero-dependency version, and 11K of .js and .astro files for the Astro version:
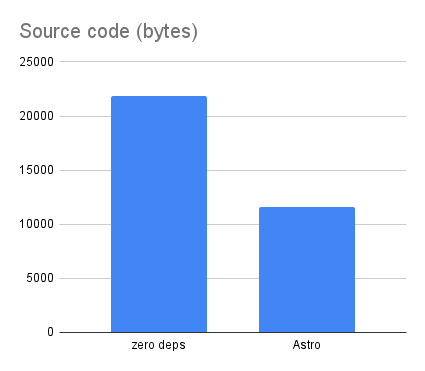
Most of the lines of code in the Astro version can be directly mapped to a corresponding line of code in the zero-dependency version; they do the same things. The extra 11K in the zero-dependency version are what implements a bespoke static site generator from scratch. (That includes 4K for an entire markdown processor.)
Now let’s compare the size of the node_modules folder for these projects. The zero-dependency version has, by definition, zero, while the Astro version has 117Mb of node_modules.
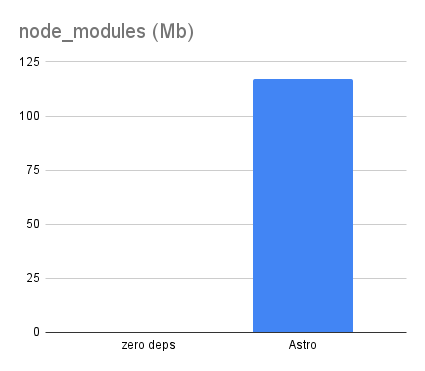
Both projects produce identical output. The extra 11K of handwritten JavaScript in the zero-dependency version is, for the purposes of this project, functionally equivalent to the subset of the 117Mb Astro actually being used by the Astro version. Those sizes can’t be compared directly, but we’re looking at four orders of magnitude of difference in size.
What is all that Astro code doing? Astro surely has tons of features that are important to somebody — maybe you! But those features are not important to this project. Maybe they’re not important to yours, either.
The complexity in Astro does have some impact on performance. I timed some builds via time npm run build on a 2024 MacBook Air M3. The first build was always the slowest, so I threw that time away and averaged the real time of the next three builds.
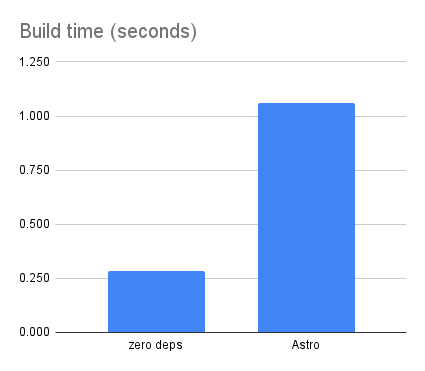
I expect the zero dependency version could be made faster, but this already looks pretty good; it’s hard to compete with plain JavaScript and zero dependencies. It’s entirely possible that Astro performs better for larger sites; recall that the zero-dependency version naively loads everything into memory, so at some point that limitation would need to be addressed. At this scale, either approach is fine, but Astro is measurably slower. Note: a 1-second build time is still good!
The point is: I think big SSG frameworks like Astro have a role to play but get used in many situations where something much simpler would suffice or may be superior.
Why not build every site this way?
Although this project didn’t require a lot of code, that 11K of extra JavaScript is generic and could be reused. It’d be reasonable to put those into a library so that similar projects could build with those pieces.
While a library may run into some of the same abstraction issues and potential for bloat as an SSG framework, a library has the critical advantage that it always leaves you in control of the action. Since a good library will do nothing unless you ask for it, in my experience it’s easier to get the results you want.
So having now written this blog three times (Origami, Astro, and plain JS with zero dependencies), I figured I may as well write it a fourth time using a library. I’ll look at that next time.
Read the other posts in this series:
- Static site generators like Astro are actually pretty complex for the problems they solve
- This minimalist static site generator pattern is only for JavaScript developers who want something small, fast, flexible, and comprehensible [this post]
- Making a small JavaScript blog static site generator even smaller using the general async-tree library
- Write a very concise static site generator with Origami expression