Making a small JavaScript blog static site generator even smaller using the general async-tree library
Using the async-tree library substantially cuts down the source code for a minimalist static site generator (SSG) in JavaScript, at a very modest cost in dependencies. The result is still fast and flexible.
In the first post in this series, I recreated a simple blog in Astro that felt complicated. I rewrote the blog in plain JavaScript with zero dependencies. This post discusses yet another rewrite, this one predicated on sharing code.
You can look at the final async-tree blog source code and the live site.
Okay, maybe a few dependencies
The zero-dependency version felt quite good, although insisting on no dependencies was a little extreme.
While half the source code was unique to the project, the features in the other half can be cleanly handled by libraries, like:
- Transforming markdown to HTML. Markdown processing can be expressed as a pure function that accepts markdown and returns HTML. A processor like marked fits the bill.
- Transforming a blog feed from JSON Feed format to RSS.
These are both pure functions, a much easier kind of dependency to take on. You decide when to call the function and what input to give it; it gives you back a result without any side effects. This contract greatly reduces the potential for surprise or frustration.
The async-tree library
The remaining sharable code in the zero-dependency version comprises generic utility functions:
- A higher-order function that maps the keys and values of an object to return a new, transformed object
- A way to read and write a file system folder tree as an object
Since these are completely generic, they’re worth sharing — so over the past 4 years I’ve been working on a library called async-tree that handles these and other tasks.
The async-tree library builds on the idea that most of the hierarchical structures we work with can be abstracted to asynchronous trees. When creating a site, we rarely care about how data is stored; we just want to render it into static resources like HTML.
Our collection of markdown documents, for example, is physically stored in the file system — but that’s irrelevant to our static site generator. All we care about are the keys (the file names) and the values (the markdown text with front matter). We can think about this collection of markdown documents as an abstract tree that could be anywhere in memory, on disk, or in the cloud:

If all we want to do is traverse this tree, APIs like Node’s fs API are overkill. We just want a way of getting keys and values. This is much closer in spirit to a JavaScript Map. Unlike Map, we can handle more cases by making our methods async.
This is the AsyncTree interface:
export default interface AsyncTree {
get(key: any): Promise<any>;
keys(): Promise<Iterable<any>>;
parent?: AsyncTree | null;
}
This is an interface (not a class) that’s easy to define for any almost any collection-like data structure. Such async collections can be nested to form an async tree — a tree of promises.
Abstractions come a cost. In exchange for a considerable degree of power and flexibility, you have to wrap your brain around an unfamiliar concept. “A tree of promises?” It might take a while to wrap your head around that.
I will say that, from several years of experience, it’s ultimately very beneficial to view software problems like static site generation as reading, transforming, and writing async trees.
Example: reading markdown, reading posts
As an example, to get the first file from our markdown folder, we can construct an AsyncTree for that folder using the library’s FileTree helper, then call the tree’s get method:
import { FileTree } from "@weborigami/async-tree";
const files = new FileTree(new URL("markdown", import.meta.url));
const first = await files.get("2025-07-04.md");
Here FileTree is roughly similar to our quick-and-dirty zero-dependency code that read a folder tree into memory. But FileTree is more efficient because it doesn’t read the complete set of files into memory; it only does work when you look up a key’s value with get.
Our posts.js function turns that collection of markdown file buffers into a completely different form: a set of plain JavaScript objects with .html names that are stored in memory. Despite these significant differences, if we want to get the first post from that collection, we can still use the same get method:
import posts from "./src/posts.js";
const first = await posts.get("2025-07-04.html");
Totally different data structure, same get method.
Example: pagination
Another reason to work with collections as abstract trees is that a consistent set of operations can be defined for them regardless of their underlying storage representations.
For example, the zero-dependency version includes a one-off paginate helper that accepts a collection of posts and returns an array grouping the posts into sets of 10. The paginated posts can then be mapped to HTML pages using the project’s own mapObject helper function.
// Group posts into pages of 10
const pages = mapObject(paginate(posts, 10), (paginated, index) => [
`${parseInt(index) + 1}.html`, // Change names to `1.html`, `2.html`, ...
multiPostPage(paginated), // Apply template to the set of 10 posts
]);
The async-tree library offers the same functionality as a general paginate function which can be applied to a tree defined by any means, including our set of posts. The paginated results can then be turned into HTML with another generic tree operation, map.
// Group posts into pages of 10
const pages = map(await paginate(posts, 10), {
extension: "->.html", // Add `.html` to the numeric keys
value: multiPostPage, // Apply template to the set of 10 posts
});
Mapping the values of a collection often implies changing the file extension on the corresponding keys, so the map function includes an extension option to easily add, change, or remove extensions.
Site definition
As with the zero-dependency version, the async-tree version of the blog defines the overall structure of the site in extremely concise fashion in site.js:
// Group posts into pages of 10
const pages = map(await paginate(posts, 10), {
extension: "->.html", // Add `.html` to the numeric keys
value: multiPostPage, // Apply template to the set of 10 posts
});
// Convert posts to a feed object in JSON Feed schema
const feed = await jsonFeed(posts);
//
// This is the primary representation of the site as an object. Some properties
// are async promises for a single result, others are async trees of promises.
//
export default {
"about.html": aboutPage(),
assets: new FileTree(new URL("assets", import.meta.url)),
images: new FileTree(new URL("../images", import.meta.url)),
"index.html": pages.get("1.html"), // same as first page in pages area
"feed.json": JSON.stringify(feed, null, 2),
"feed.xml": jsonFeedToRss(feed),
pages,
posts: map(posts, singlePostPage),
};
That’s the whole site. This is the most concise way I know to define a site in JavaScript.
I find this kind of concise overview invaluable when I return to a project after a long break, and a quick glance refreshes my understanding of the site’s structure.
Build
Once the site is defined, building the site is just a matter of copying files from the virtual world to the real world. Here’s the whole build.js script:
import { FileTree, Tree } from "@weborigami/async-tree";
import site from "./site.js";
// Build process writes the site resources to the build folder
const buildTree = new FileTree(new URL("../build", import.meta.url).pathname);
await Tree.clear(buildTree); // Erase any existing files
await Tree.assign(buildTree, site); // Copy site to build folder
The async-tree library provides a set of helpers in a static class called Tree. These provide a full set of operations like those in the JavaScript Map class so that AsyncTree interface implementors don’t have to define those methods themselves, making it easier to create new AsyncTree implementations to read data directly out of new data sources.
Assessment
We can compare this async-tree version of the blog with the earlier Astro and zero-dependency versions. All three versions create the same site.
The async-tree version makes strategic use of libraries for markdown processing, RSS feed generation, and manipulating objects and files as trees. This removes over half the code from the zero-dependency version, so async-tree has only 9K handwritten source code, the smallest of the three:
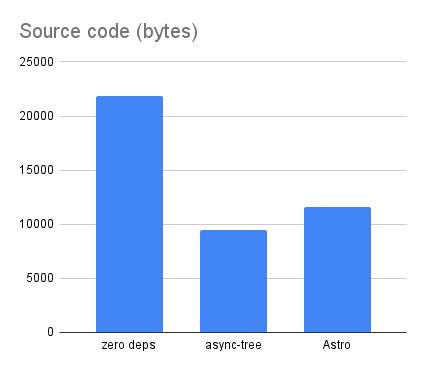
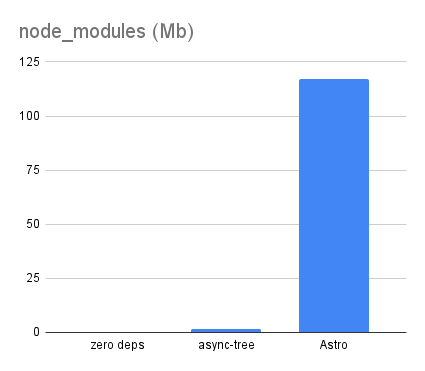
This comes at a modest cost of 1.5Mb of node_modules, or about 1% of the 117Mb of node_modules for the Astro version:
The async-tree version is still extremely fast, just a hair slower than the zero-dependency version:
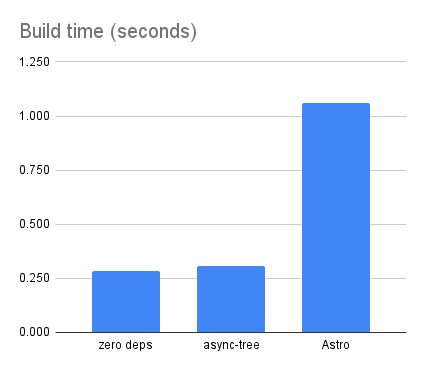
Nice!
Impressions
Like the zero-dependency version, this async-tree version was fun to write.
The introduction of a limited set of dependencies to this project felt fine. The small libraries I’m using here all do their work as pure functions, so I’m still in control over what’s going on. I don’t have to wrestle with plugins, lifecycle methods, or complex configuration like I would have to in a mainstream SSG framework. I’m just calling functions!
Debugging async JavaScript code is harder than debugging regular, synchronous code. The debugger I use in VS Code does a fairly good job of it, but it’s still not possible to inspect the value of variables across async stack frames. That can make it harder to figure out what’s gone wrong at a breakpoint.
That said, I once again made good use of the ori CLI to check various pieces of the site in the command line. That let me confirm that individual pieces worked as expected, as well as serve the site locally to inspect the evolving site.
All in all, I think this async-tree approach is a really interesting way to build sites. It’s significantly less JavaScript than the zero-dependency version, while it’s still very fast and light on package weight. You stay in control.
Since I wrote the async-tree library, I can’t provide an objective assessment of how difficult it is to use.
The library deserves more comprehensive documentation than it currently has; I’ve generally focused my documentation writing on the higher-level Origami language and its set of builtins. If you’re intrigued by this more foundational, general-purpose async-tree library, let me know. I can help you out and prioritize documenting it in more detail.
Improvable?
As small and focused as the source for this async-tree version is, it can be made even smaller! Next time I’ll revisit the original sample blog that started this post series and show the benefits of writing it in Origami.
Read the other posts in this series:
- Static site generators like Astro are actually pretty complex for the problems they solve
- This minimalist static site generator pattern is only for JavaScript developers who want something small, fast, flexible, and comprehensible
- Making a small JavaScript blog static site generator even smaller using the general async-tree library [this post]
- Write a very concise static site generator with Origami expression