OpenID: Great idea, bewildering consumer experience
A while back I tried signing up for an OpenID, an "open, decentralized, free framework for user-centric digital identity." The basic idea is that, instead of needing to choose a user name and password for every site you visit, you can identify yourself with an ID that many sites will accept. It sounds great, but in practice I found the whole process bewildering. In my opinion, it’s not ready for consumer use.
Beyond security criticisms of the scheme that can be found elsewhere, I think OpenID has some significant user experience issues. Some of the problems can be fixed, others are integral to the way the system works.
- It’s way, way too hard to get started. All the sites supporting OpenID point curious users to the home page for the OpenID Foundation. From this site, it’s actually stunningly difficult to find a link to a place where you can actually get an OpenID. A link to a site called I want my OpenID! sounds promising, but the destination page doesn’t actually deliver on the promise of getting a user an OpenID either.
- The content and tone of the OpenID Foundation site is oriented at developers, not end users. The second sentence of the home page boasts, "OpenID starts with the concept that anyone can identify themselves on the Internet the same way websites do—with a URI." You know what? To most people, that doesn’t sound like an advantage; it sounds geeky, dehumanizing, and more than a little bit frightening.
- While there are very cool benefits that come from identifying oneself with a URL (URI), pity the poor consumer. They have dutifully learned that a user name is an identity and a URL is a place to go. Now they must wrap their weary brains around the concept that, when asked to identify themselves, they should provide a location. "Why can’t I just use my email address?" they’ll wonder.
- The process of selecting an OpenID provider will stump the average consumer. They’re being asked to pick an ID that they will, in theory, use everywhere and forevermore to gain access to everything they own. They’re supposed to obtain this ID by making an effectively random selection from a group of providers they have never heard of.
- Various OpenID sites also promote the notion that users should set up their own OpenID provider. This is fine for a teeny tiny portion of web users, and scary and out of the question for everyone else.
- The lists of OpenID providers are presented in a static order. In some cases this will be alphabetical. The most commonly referenced list of OpenID providers is presented in chronological order of when the service went live, an order that is effectively random. It’s not immediately clear in most of these lists why a user would pick one provider over another. None of the lists I’ve seen are organized around attributes which are relatively easy for a user to base a decision upon, like: Do you have a blog already? Or, Which language do you prefer to speak?
- As an aside, when you ask a normal person to choose a provider from a list for a service they don’t understand, most people are just going to pick the first or last entry. (If a default value is provided, they’ll pick that. The default value will almost always be the first entry.) So, a static list of providers turns out to be a really good way to screw the bulk of providers whose entries sit in the middle of the list. Microsoft learned this lesson the hard way in various places in Windows, addressing such problems by dynamically shuffling provider names so that all providers spend equal time at the top of the list. More usefully, the lists could reflect community-based provider ratings.
- The ostensible universality and permanence of an OpenID actually makes the task of picking a provider harder. Even if I happen to currently have a SixApart blog with a TypeKey, am I really prepared to use that ID everywhere? Exactly how long can a consumer expect a given OpenID provider to remain in existence? In my playing around on one site, when I remapped a URI from one provider to another, I lost my ID-related preferences. This gives me pause in depending upon any provider that could potentially die before the web service I’m using the ID with. Frankly, many of the OpenID providers seemed like tiny organizations that could disappear overnight. Nowhere could I find anything that would tell me what should theoretically happen to my ID-bound accounts if that were to happen.
- Suppose that, at some point, a visitor to an OpenID-enabled site is really intrigued by this OpenID thing they keep coming across, and decides on the spot that they want to get one for themselves. The OpenID community, and the sites that use it, appear to have given little thought to addressing this scenario. Go to the LiveJournal home page and try figuring out how you’d get an OpenID and come back to use it. I’ll bet analytics on the site will show that, of the tiny percentage of visitors to LiveJournal who go off from there to get an OpenID, only the most determined will make it back. Why would a site operator let anyone leave their site to perform a task from which they will never return?
- An OpenID is an identity (like a user name), not an account. A consumer still needs an account to use the site. However, this isn’t at all obvious to a consumer. When I tried to sign in to Plaxo with my OpenID, I got an otherwise blank page displaying the error, “Unable to verify the specified OpenID.” Some sites do a reasonable job of letting a user who has never logged on before create an account on the spot. When I tried to sign in to LiveJournal with my OpenID, they let me create an account and then start using it. This inconsistency among implementations will confuse a lot of people.
- When I actually tried to use my OpenID on a site, I got a confusing message from the OpenID provider requiring me to confirm that I really wanted to let the site access personal information I had associated with my OpenID. The clarity of such messages varies from OpenID provider to provider, ranging from puzzling to incomprehensible. In the case of Verisign, I was instructed to select which “Trust Profile” I wanted to associate with the site—or did I want to create a new Trust Profile? Wha?
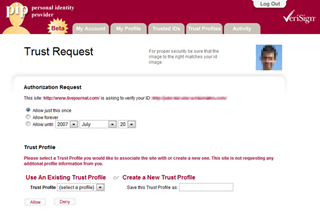
Since most users have never encountered the concept of sharing information across sites, a ton of education would be necessary to make these messages meaningful to the average user.
- Currently, even those sites that do implement OpenID generally treat OpenIDs as a second-class form of identification. They put their own proprietary means of signing in (generally with a user name and password) on their home page, and bury the OpenID sign in facility behind a link. This means that the hip OpenID-using visitor has to make more clicks than the proprietary ID-using masses… which doesn’t exactly sound like a reward.
And all this is for—what, exactly? To save me from having to pick a user name and password? As annoying as that can be, it’s just not that hard! Remembering an arbitrary user name does cause real trouble, but simply allowing email addresses to be used as IDs can solve almost all of that problem. As more and more sites allow email addresses as IDs, the need for OpenID becomes less compelling to a consumer.
For the time being, I can’t imagine a sane business operator forcing their precious visitors through this gauntlet of user experience issues just for the marginal benefits that accrue to a shared form of ID. I’ve read numerous claims that all it will take is for someone big like Google to support OpenID to crack this problem open. Unfortunately, there’s no business of any size that can afford to direct their traffic down a dead end.
Most service operators will, at best, offer users a choice between using a proprietary ID or an OpenID, creating a terrible economic proposition for a consumer. Faced with the proposition of: 1) struggling once for thirty minutes to struggle through a process they can barely understand, or 2) spending two minutes on every new site breezing through a familiar process they’ve done countless times before, normal busy people will choose the familiar route time and time again. I’ll bet anything that most people will keep going for proprietary IDs, further deferring the network effects possible from OpenID adoption.
This isn’t to say that OpenID isn’t worth attempts to fix it. At least some of the above problems can, and should, be addressed head on by the OpenID community. My recommendations:
- Redesign the OpenID home page for consumers. The page’s main content should contain a brief explanation of OpenID in consumer-friendly terms, along with a giant Get an Open ID button. Move all the developer material behind a Developers button.
- Design an end-to-end process for getting an OpenID from a service operator’s site. Since most services won’t care which provider the user uses, let these services send the user into a real flow for picking a provider, getting an ID, and most importantly coming back to the original service to use the new ID. When they get back to the service, the new OpenID should be prefilled.
- Give the above flow a sidebar titled "Do you have a blog?" that explains that, if they have a blog on LiveJournal, TypePad, etc., they can use that for their OpenID. A link in the sidebar should shunt the user into a page that has them pick their blog provider, then tells them what the (blog service dependent) form of their OpenID is. The flow should then return the user to the service they started on (again, with their OpenID prefilled).
- Organize the list of providers around factors that can actually influence a user’s decision. Consider offering provider ratings based on ease of use, uptime, etc.
- Refine reference designs for the complex range of cases that come up in using OpenID with a service. E.g., define the expected behavior and terminology that should be used when a user tries to log in with an OpenID but does not already have an account with that ID.
- Define guarantees that services should offer to users in the event their OpenID provider goes out of business.
- Build an organization that can do real usability testing on this service with real consumers.
UPDATE (October 7, 2007): This week OpenID.net overhauled their site, and the new site addresses a number of the criticisms listed above.