To test a site-crawling feature for Web Origami, I thought I’d crawl the original 1996 Space Jam site. The site’s often referenced as proof of HTML longevity, but I’ve only ever seen the site’s famous “solar system” home page:
Having seen this home page countless times, I’d assumed the site was tiny — maybe a dozen pages?
I was wrong. The site is freaking MASSIVE.
Over 350 HTML files! Over 600 images! Audio clips! Videos! VR videos!
A map of the whole site gives a sense of scale. Click to open and explore, but, um, you’ll need to pan around or zoom out.
It’s entertaining to spelunk through this massive ancient site.
All the HTML appears to generally work as it did when it was written. Some of it is antiquated, like the use of <frameset>.
It’s been a very long time since I saw anyone capitalize an HTML tag name or attribute like HREF or SRC. Still works, though!
The <body> tags make use of a backgroundattribute that lets you pass a URI for a background image. MDN says: Do not use this attribute!
The site has lots of image maps — but I don’t remember ever seeing a .map file before even back in the day when the site was made. I can’t find documentation for .map files on MDN, or real docs for them anywhere.
The Neat Stuff page contains links to “full-size versions” of some images. The “full-size” images are 300×216 pixels in size. 🖼️🔬🤣
The Browser Icons page explains how Mac users can change the icon for their copy of Netscape Navigator using the ResEdit resource editor!
The site appears to include some QuickTime VR movies, but I can’t get those to work. The web community generally cares more about backward compatibility than Apple does about its own tech.
The original site appears to have not used separate .css files. The current site does have a single .css file for a policy notice, presumably added later. If you compare the current site with snapshots in the Wayback Machine, you can see Warner Bros. occasionally updates the site. It’s great that the current site has an “Accessibility” link to their accessibility policy, but that link was added long after the movie.
Oddly, there are two copies of the home page at jam.htm and jam.html. The second one is only linked to by a moribund Press page. Someone may have updated that page later to remove the news stories and assumed the home page had a modern .html extension. Someone later noticed the broken link, but instead of fixing it created a second copy of the home page.
Poring over it, I think the original Space Jam site is a remarkable artifact.
For an early site, it’s breathtakingly ambitious and executed to a consistent level of production values.
It’s a beautiful work in a then-new medium, with the creators trying to match what they wanted to say with what they thought their audience would want or were ready for.
This immense, handwritten and hand-tested pile of HTML contains remarkably few errors. The site contains 1,954 handwritten <a> tags, but of those the Origami crawler only finds 3 links which are broken.
The site continues to serve as a premier example of the web platform’s admirable, vital commitment to backward compatibility.
Kudos to the people behind the site: executive producer Donald Buckley, producer Dara Kobovy-Weiss, designers Jen Braun Davies and Andrew Stachler, and writer/coder Michael Tritter. And kudos to Warner Bros. for keeping the site up!
If you want to inspect the site yourself (or one of your own sites), you can crawl and copy it using the following command (requires Node to be installed but no other pre-installation):
Origami’s crawl command doesn’t throttle requests, and doesn’t try to recover dropped files, so it may not copy everything. Once the site is copied, you can serve it with whatever server you like, or:
npx @weborigami/origami @serve @debug spacejam
The @debug option gives you the ability to produce interactive maps like the one above from the served site. In the browser, go to any local URL and add /!@svg to the end of it, e.g.:
In a humane world, people would start interacting with an open source project by saying “I ❤️ your work” and “Here’s what I’m using it for.”
In our world, the first time a maintainer learns of a customer’s existence is usually when the customer files a bug. That’s like walking up to an author you’ve never met and opening with “Here’s what I hate about your book…”
That’s shitty behavior in real life, and just because we’ve somehow tolerated it in the industry doesn’t mean it can never be fixed. Repos could, say, have a means by which customers can introduce themselves, say what they like, and describe how they’re using the project.
Since we don’t have that world yet, I’m making an effort to proactively and publicly praise projects I like. I’ll start by acknowledging the great work of Joe Hildebrand and the other contributors on the Peggy parser generator for JavaScript. It’s a nice project, and just what I needed!
I’d handwritten a parser combinator for Graph Origami, a good way to start but had poor performance. I decided to try writing a parsing expression grammar (PEG) using the Peggy parser generator. The docs and sample grammars were helpful, and the long life of Peggy and its predecessor peg.js meant ChatGPT could help answer questions for me. Porting to a new Peggy-based parser only took a day. The new parser is faster, doing the same work in 10–15% of the time.
I’ve made a video to introduce Graph Origami: a novel conceptual framework and toolset for building websites and other digital content using graphs as foundational design and development artifacts. This approach makes frontend and backend development in JavaScript enormously productive (and fun!).
Some features shown in the video:
A high-level expression language for quickly building websites
A general pattern for treating a wide range of data sources as graphs
A JavaScript core library for creating and working with graphs
A general-purpose tool for calling JavaScript and working with graphs in the command line
A demonstration of treating services like Google Drive as abstract graphs
I’ve been researching this approach for over two years and continue to be regularly delighted by what it lets you accomplish. If I can conceptualize what I’m trying to do as operations on a graph, the code required to express that tends to be concise and work the first time.
Graph Origami is not yet a product but is ready for you to try. I’m specifically looking for people who might be interested in collaborating on applying these ideas to their projects — I want to see how this approach works in a wider range of applications, and ensure the project evolves in a direction you’d find useful. If this sound interesting to you, please contact me.
The Unicode emoji proposal process is open to the public in theory, but as far as I can tell, is currently accepting a tiny number of proposals based mostly on “things people like”. I submitted an emoji proposal for Person Pointing at Self, which was rejected.
The subcommittee has a challenging role. Adding emojis to every device (particularly cheap ones) has a real cost, and they want to keep costs low for their vendor members. At the same time, they want to satisfy/appease the world’s screaming demand for more emojis. The subcommittee’s publicly stated selection factors for emoji are:
compatibility
usage level
distinctiveness
completeness
That said, the committee rejected an emoji to represent “I”/“me”: possibly the noun with the highest frequency word across all languages, and one with thousands of years of consistent visual representation. There must be other factors at play.
Reading recent approvals like the new emojis in Unicode 15.0, we can infer that the subcommittee applies additional, undocumented criteria, which may include:
Is it a heart or a face? People like those.
Is it a popular food or charismatic fauna/flora? People like those.
Is it an important cultural totem? Please like those — and it’s hard to tell a large group they don’t deserve representation.
If these really are something like the criteria applied to new proposals, the subcommittee leads people to waste their time crafting proposals that have no chance of being accepted. And limiting new emoji to “things people like” is a crabbed vision of what emoji could do for humanity. Focusing on things people actually talk about seems like a better, less arbitrary metric that would enable more substantive communication.
The one bright spot in the emoji submission process were the wonderful people at Emojination, especially emoji maven Jennifer Lee. She was the producer for the movie The Emoji Story (which is worth a watch), and leads an active and supportive Slack channel for emoji proposals. If you have any interest in submitting a proposal, I’d start there.
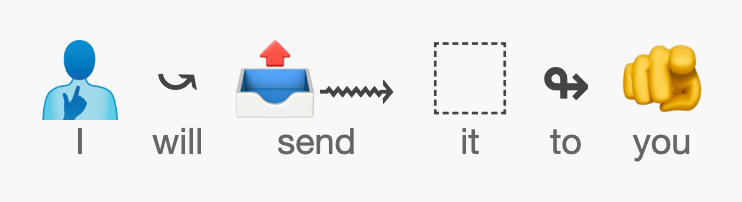
A while back I submitted a proposal to Unicode for a new emoji to represent “I” or “me”: Person Pointing at Self.
Given the ubiquity of this gesture around the world, I felt the value of this emoji was self-evident.
While this emoji proposal grew out of my tinkering on the Emojese emoji language, the emoji is language-independent; you could use it while texting in any language. If you open Emojese and turn on Experimental Emoji, you can try typing “I” or “me” in a sentence and see what it would be like to use Person Pointing at Self for this purpose.
Submitting an emoji proposal requires gathering a pile of data to address the emoji selection criteria. One criteria is durability: “Is the expected level of usage likely to continue into the future, or would it just be a fad?” There are examples of written hieroglyphs using this point-at-self gesture from ancient times. The Dongba script in southern China has been used for over 1000 years ago and is still in use today.
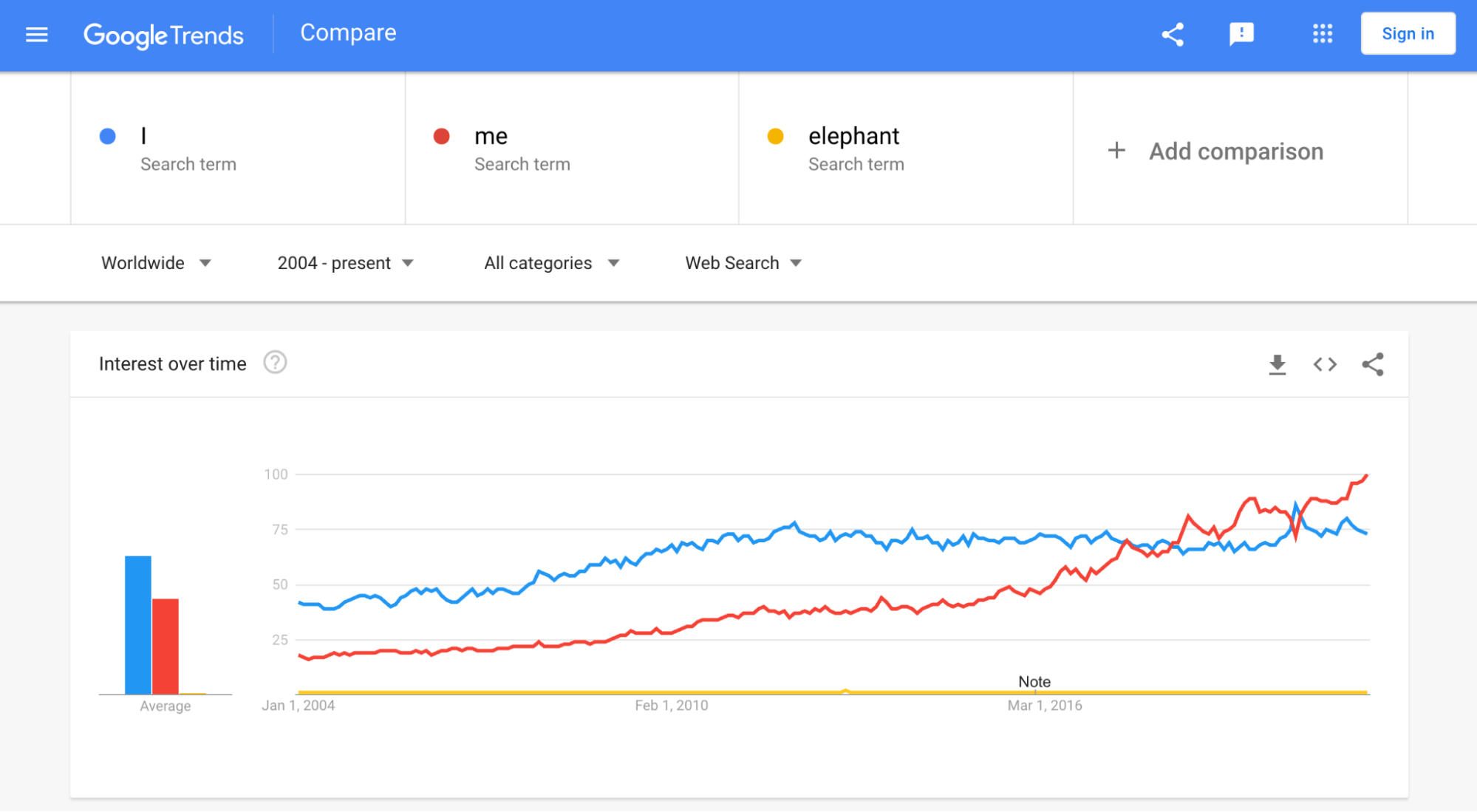
Your emoji proposal must also assess possible usage of your proposed emoji by comparing web search hit counts for the terms it represents against uses of the reference term “elephant”. Let’s see how searches for “I” and “me” stack up.
Hmm, the terms I/me are so incredibly popular that the baseline “elephant” term is indistinguishable from the x-axis. People talk about themselves more than anything else! This trend probably holds true across any time period or culture you care to examine — even the ones with lots of elephants.
An emoji intended to represent “I”/”me” doesn’t just beat any existing emoji proposal on usage and durability, it will likely beat all future proposals too.
While developing vocabulary for the Emojese emoji
language, I’ve found many common words that might benefit
from new emoji. You can turn on Experimental Emoji in the app to see how
these could feel in practice.
I think it would be worthwhile to deliberately fill out Unicode with emoji for the many common words without obvious emoji representations. Some of these concepts are quite abstract; any visual representation might be challenging, especially at small sizes. The Unicode Emoji Subcommittee requires new emoji proposals to be legible at 18x18 pixels, which is quite small. Still, you can get a sense for just how many of these concepts can be represented well.
The Emoji Subcommittee is very conservative these days when it comes to approving new emoji — but in recent years the same subcommittee approved 150 emojis for a single idea: 💑 Couple with Heart.
People justifiably want to see themselves represented, and in the case of 💑 that requires supporting two people, three genders (female, male, neutral), 6 skin tones (including the default yellow tone and the 5 skin tone modifiers). The combinations add up quickly.
Clearly “love between two people” is an important concept, but we do talk about many other things in our daily lives, and a substantial number of those don’t have any clear emoji representation yet.
Imagine if we introduced 150 new emojis to represent actions and ideas which are extremely common in everyday conversation but which have no obvious representation today! Surely that would be worthwhile?
Emoji week continues! With emoji as an expanding foundation for cross-cultural communication, I don’t think it’s a stretch to envision the eventual emergence of a basic grammar and the identification of existing emoji for specific abstract meanings. Emoji will form the basis of a written pidgin language: a simplified language that is incomplete but can nevertheless fill a useful role.
Emoji dramatically extend the world’s set of commonly-understood symbols. There were universal symbols before emoji, but they were generally confined to domains like math, science, and music. Emoji has increased that universal set by an order of magnitude. I assume it’s also shifting what can be understood across cultures.
As a software designer in the 1990s, I received instruction from international localization teams to avoid using gestures like 👍 in icons because some cultures interpreted them as offensive. As software has eaten the world, the culture of its makers has spread as well. I assume that in the context of software most people around the world can now recognize the intended positive meaning of 👍 regardless of their cultural background.
Any specific constructed emoji language like the Emojese emoji language is unlikely to take root — but we can watch for something similar to spontaneously emerge and spread around the world. Isn’t that a beautiful idea worth encouraging?
My guess: a group of charismatic young musicians stretches emoji into a pidgin as a way to connect with their global fanbase of teens, who pick up the pidgin to express their enthusiasm and connect across a language boundary. Thirty years later, those fans can stay at an AirBnB with checkout instructions like ◐⏰ 🫵 ⎋, 📦⬇️ 🚮⬚ 📥 🗑️ ⩕ 🚗Ⓟ📍
Creating a written language from emoji is challenging. Any constructed visual language faces the problem of identifying vocabulary. This problem is even harder with the Unicode emoji set, which is skewed to faces, hearts, animals, occupations, foods, flags, and cultural totems. There are many common words without obvious emoji representations.
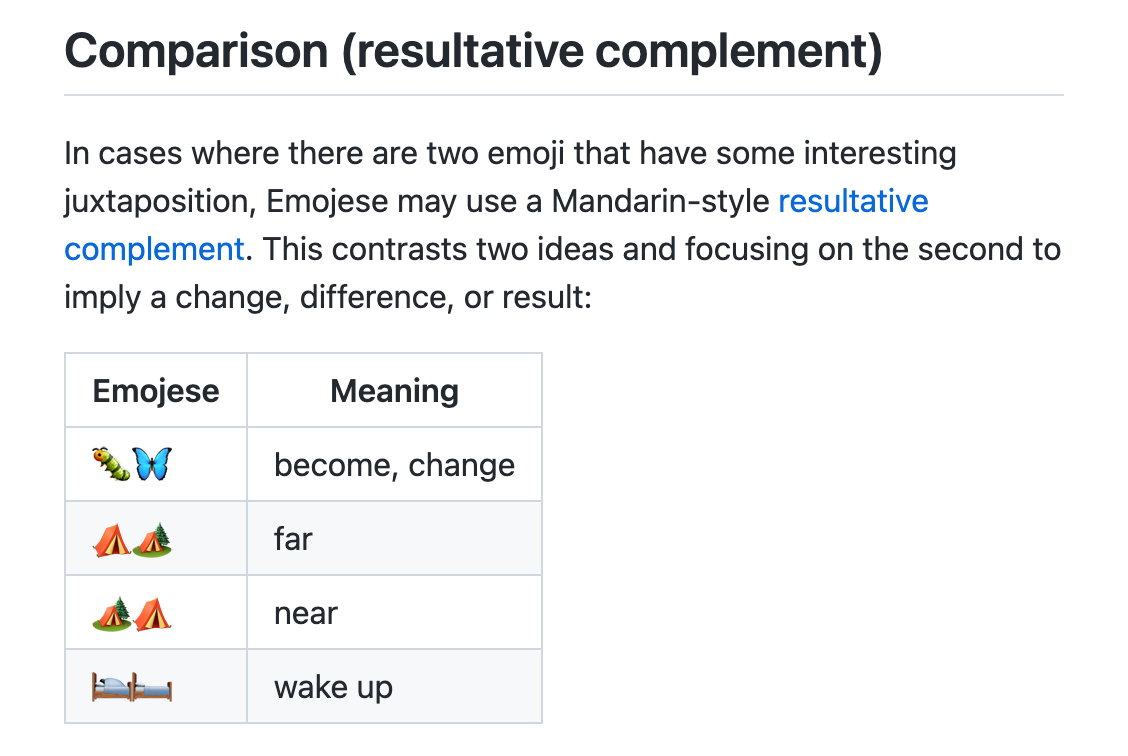
To compensate for this, the Emojese emoji language resorts to a number of strategies to identify emoji sequences that can represent something new.
A particularly productive strategy is to designate certain emoji or glyphs to communicate abstract ideas and incorporate these into larger glyphs to contribute those abstract meanings. Chinese and Japanese kanji have characters called “radicals” that express such core meanings. For an emoji language, we can pick specific emoji and Unicode glyphs to fill the same role as radicals in emoji sequences:
The goal is to produce sequences which, while perhaps not obvious on first reading, are good enough and consistent enough to be remembered. Using this and other strategies, Emojese now has 1000+ common words, which is large enough to be general purpose and to communicate some complex ideas.
The Emojese emoji language is rich enough to express complex thoughts entirely in emoji and other Unicode glyphs.
I think emoji languages are a fun idea, but when I looked for one in 2020, I couldn’t find anything that was: a) satisfying, and b) sendable as real text. My kids and I explored ideas which I formalized into Emojese and embodied in the above app for writing and reading sentences. Emojese is a pidgin language with a handful of grammar suggestions and emoji definitions for 1000+ words.
A friend and I had a ton of fun texting back and forth in Emojese for several months — a 🕵️ Secret Decoder Ring for texting! Before long, we could read many messages before decoding them in the app. I expect you would experience similar results.
All emoji languages initially look silly/overwhelming — it’s hard to read so many unfamiliar images, the choice of symbols feels arbitrary, and the constraints of existing emoji result in unfamiliar pairings like 👉☀️ for “today”.
The best I can hope for is that, after seeing a translation, you feel it’s reasonable and that the few unavoidable abstract symbols are memorable. If the language is consistent in using 👉 as “this” and “☀️”, then 👉☀️ for “this day”/”today” begins to feel acceptable.
This lets you write things roughly like Randall Monroe did with a 1000-word vocabulary in his Up Goer Five comic and Thing Explainer book — only in emoji. 🔮⋯ ⬚👈 ▶️ 👉⟿ ↬ 🌌 ⇒ 🫵 ⤻💁 👎 😬💦 & 🫵 ⤻🚫 → ↬ 🌌 👉☀️
One of my kids and their high school friends had fun playing with Emojese messages on their Discord server. It took about 10 minutes for the conversation to veer into insults like 🫵の👩🍼. I was happy they were entertained — the whole point of the project is let people have fun.
For the new year, I consolidated content from three earlier blogs to create a new blog at https://jan.miksovsky.com. This includes content from: a) flow|state, a UI design blog I wrote from 2005–2014, b) a blog for my UI component framework called QuickUI from 2012–2013, and c) the blog for my second startup, Component Kitchen, which was generally focused on web components from 2014–2020.
My goal has been to create a single site for my professional work. I’ve been invigorated by the resurrection of interest in blogging spurred by Twitter’s recent self-immolation, and by my general growing interest in removing corporate gatekeepers from our public presences.
I did the porting and consolidation, as well as the ongoing serving of it at this new location, using a new set of tools I hope to begin discussing publicly soon.