It’s always useful for me at the end of the year to reflect back on the past year’s work. I think this has been a great year for the Web Origami project and the Origami language.
Goals for 2024
At the start of the year I set some specific goals for the project, all in service of building awareness of the project. These were all in addition to the regular investments in the Origami language, runtime, builtins, etc.
Goal 1: Create a small but realistic sample application every month
I kept this up for six months, producing the set of apps on the Examples page:
Cherokee Myths — generate a table of contents, incorporate full-text search
Japan hike ebook — using ZIP/EPUB tree driver to create an ebook
pondlife — sample blog, made available as origami-blog-start starter project
I’m quite happy with this set, and I think they’ve been helpful in illustrating some of what Origami can do.
Halfway through the year I felt like I’d reached the point of diminishing returns; adding one more to the set isn’t going to be the thing that tips the balance for a newcomer. And going forward actual user sites will also be good examples for others to follow.
Goal 2: Daily efforts to promote Web Origami
Marketing doesn’t come naturally to me, so I tried to make myself spend substantial time doing it. I wanted reach out to at least one person each work day with an email, social media post, blog post, etc.
I was only able to keep this up for a few months before getting exhausted. As it turned out, that might have been enough anyway.
Goal 3: Pitch Web Origami presentations to three conferences
I did this — but none of the conference accepted my talk proposals.
Submitting a conference proposal is real work, and I’ve come to believe that it’s a waste of my time.
As a matter of policy, conference organizers give you zero feedback on your submissions so it’s hard to improve them.
When I looked at talks that were ultimately accepted by these conferences, I was disappointed: many talks promoted technologies that already have a lot of awareness, so the conference just fanned the flames of something that’s already popular.
The world of conferences is supported by payola: companies pay conference organizers a “sponsorship fee” to get a talk accepted. I can’t afford that, and in any event find the practice appalling. I sat through a one-day conference this year that felt like binging 10 hours of informercials.
The one conference I particularly wanted to speak at was the StrangeLoop conference. Sadly, in January 2024 I looked for their CFP and was crushed to learn that 2023 had been the final year of the conference.
I would love to present Origami at a conference at some point but can’t afford to waste more time on talk proposals that will just get rejected. I’ll only invest the time to prepare a talk if invited to do so.
Feature work
I am incredibly fortunate to be able to work on the Origami language full time. I was able to invest in a long list of new or improved features for the language. Most of the investments I made in the second half of the year were based on user feedback.
By far the most exciting news this year was that people began using Origami to make sites with it. At the beginning of the year I was the only one with Origami sites in production; now there are a couple of user sites and a few more are in development.
These early adopters provide invaluable feedback on what kinds of sites real people want to make, and whether Origami makes it easy for them to make those kinds of sites.
I’m looking forward in 2025 to fostering the community of Origami users and directing substantial investments in the project based on their feedback.
I’ve posted a new Origami intro screencast that covers some of the basics of the Origami language:
This screencast doesn’t give a complete introduction yet, but I think the production process I’m using is itself interesting and worth sharing.
Videos are a vital form of documentation but:
Videos take forever to produce — for me, easily an hour or more of production work per minute of final video!
Videos documenting an evolving language quickly become out of date. I’ve poured weeks and weeks into videos that are already woefully out of date and have had to be taken down to avoid confusion.
What I really want is to be able to focus on the story I want to tell — to be a screenwriter. I want to write a screencast script with stage directions (“Click on index.html”) and dialogue (“Alice: This index.html file contains…”). I’d love to be able to generate a decent screencast video directly from that.
Process
I can’t find anything that lets me do what I want, so for now I’m trying to automate generation of the video and audio separately.
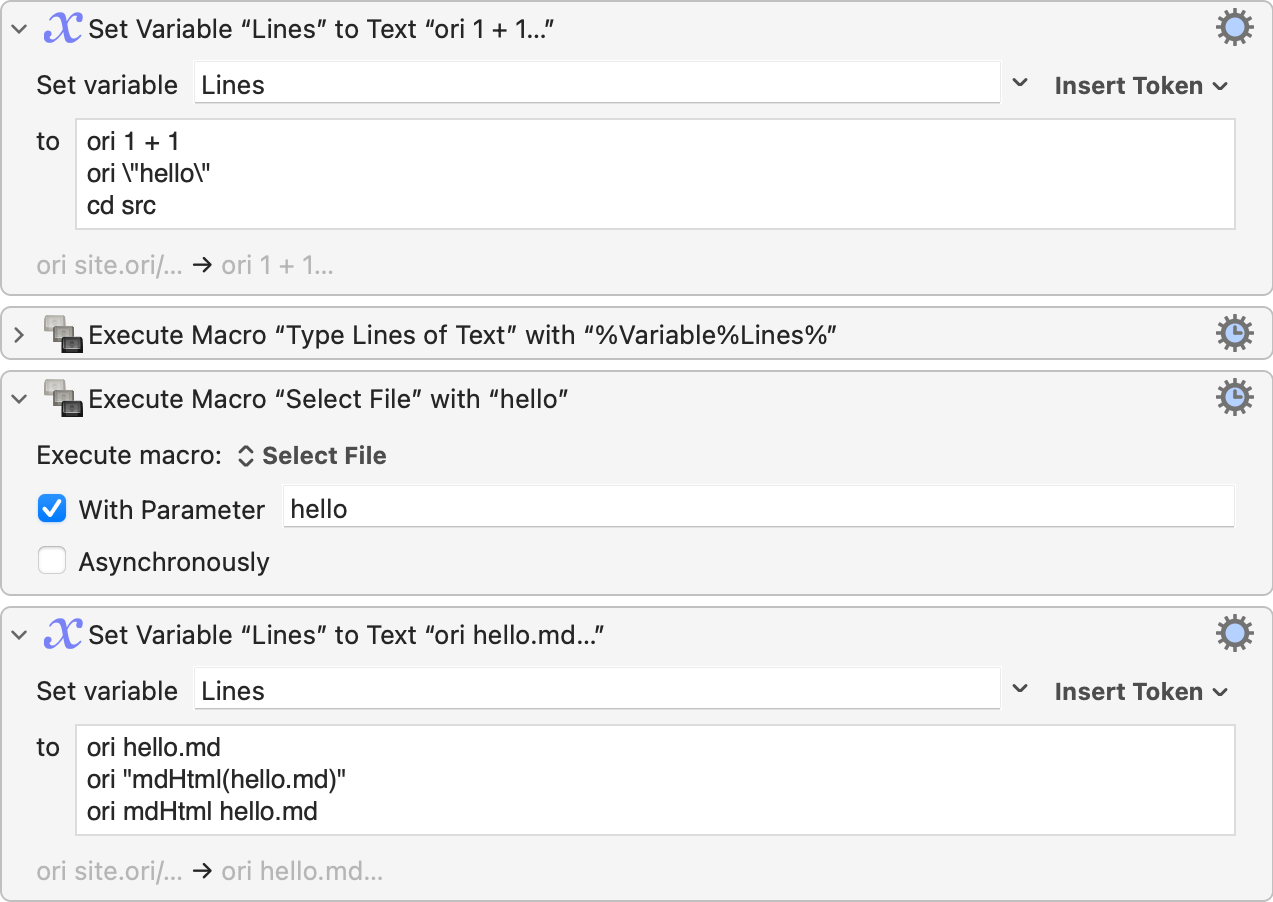
I’m trying a scriptable mouse/keyboard desktop automation product called Keyboard Maestro. I can write keyboard/mouse macros for specific common actions (open the VS Code terminal, select a file, etc.), then assemble these into an overall macro for the screencast.
This is very clunky for this purpose; I really wish some product like this offered a real programming language. In any event, I play the macro while recording the screen to get the video portion of the screencast.
The script is a YAML file with lines of dialogue for each of the “actors”:
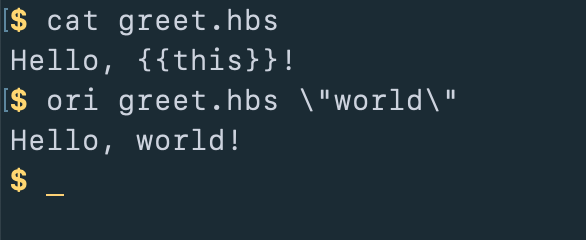
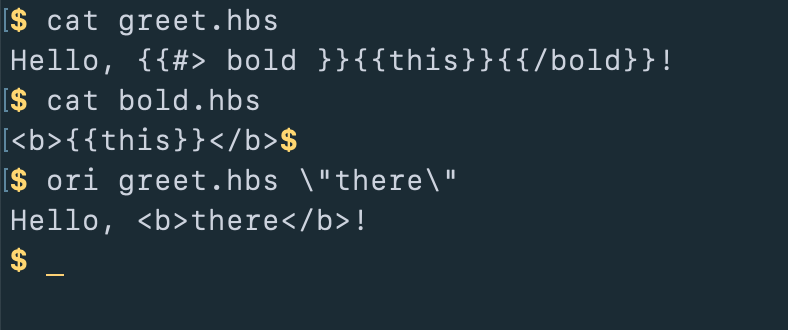
-echo:>
To illustrate the basic ideas in their plainest form, let's start by writing
some expressions in Origami using the command-line interface called ori. If
I type "ori 1 plus 1", it evaluates that and displays 2.
-echo:>
If I type "ori hello”, oree displays hello. In the shell, you'll need to
escape quotes or surround them with extra quotes because the shell itself
consumes quote marks.
-shimmer:>
In addition to basic numbers and strings, you can reference files. Think of
each file as if it were a spreadsheet cell. Instead of the A1, B2 style cell
references in a spreadsheet, we can use paths and file names to refer to
things. Unlike most programming languages, names in Origami can include
characters like periods and hyphens.
This produces the audio portion of the screencast.
I then use Camtasia to merge the audio and video to create the final screencast file. This requires a fair bit of work to position the audio clips in relation to the video, and in many places to add delays in the video to give the audio time to play.
Lessons
This editing process still takes time but the recording of the audio and video took very little time compared to previous screencasts. And if Origami changes, it’s feasible to tweak the demo macro or dialogue, rerecord those, and splice those into the screencast.
I posted this video on the Origami discussion board to get feedback on a draft screencast. I used that feedback to refine the audio and video and then spliced in the updated parts. Being able to iterate on a screencast is fantastic.
One unpleasant surprise: After a second round of feedback, I went to rerecord the video — and discovered that VS Code had made changes to its window chrome! Uh, rats. That means that new video clips can’t be used alongside old ones, which means having to reposition all the audio in relation to the new video. That’s a real time sink.
Future
I hope this approach pans out so that I can make more useful screencasts that can stay relevant for a longer time. Towards that end, I’d love to be able to:
Replace the use of a keyboard/mouse desktop automation with something that has a real programming language, ideally JavaScript.
Annotate the desktop automation script with the dialogue so that I can somehow programmatically sync the audio and video tracks.
Alternatively, create a way to render something that looks like a generic code editor (and browser) with enough functionality to illustrate the kinds of points I make in screencasts, and where I can drive all the activity through code.
If you’re familiar with tools that can do any of those things, please let me know!
I’d love to find a few new people to try out the Origami programming language for creating websites — maybe you?
Maybe you have any of these goals:
Are thinking of making a site for a passion project but aren’t sure how
Have an existing site you want to move off a platform (WordPress, say) to something you control
Want to try rewriting a site to add more features
Want a site where you understand how it’s made
and you:
Are familiar with basic HTML and CSS (JavaScript knowledge is not required)
Can use a code editor (doesn’t matter which one)
Have some minimal experience running commands in a terminal window
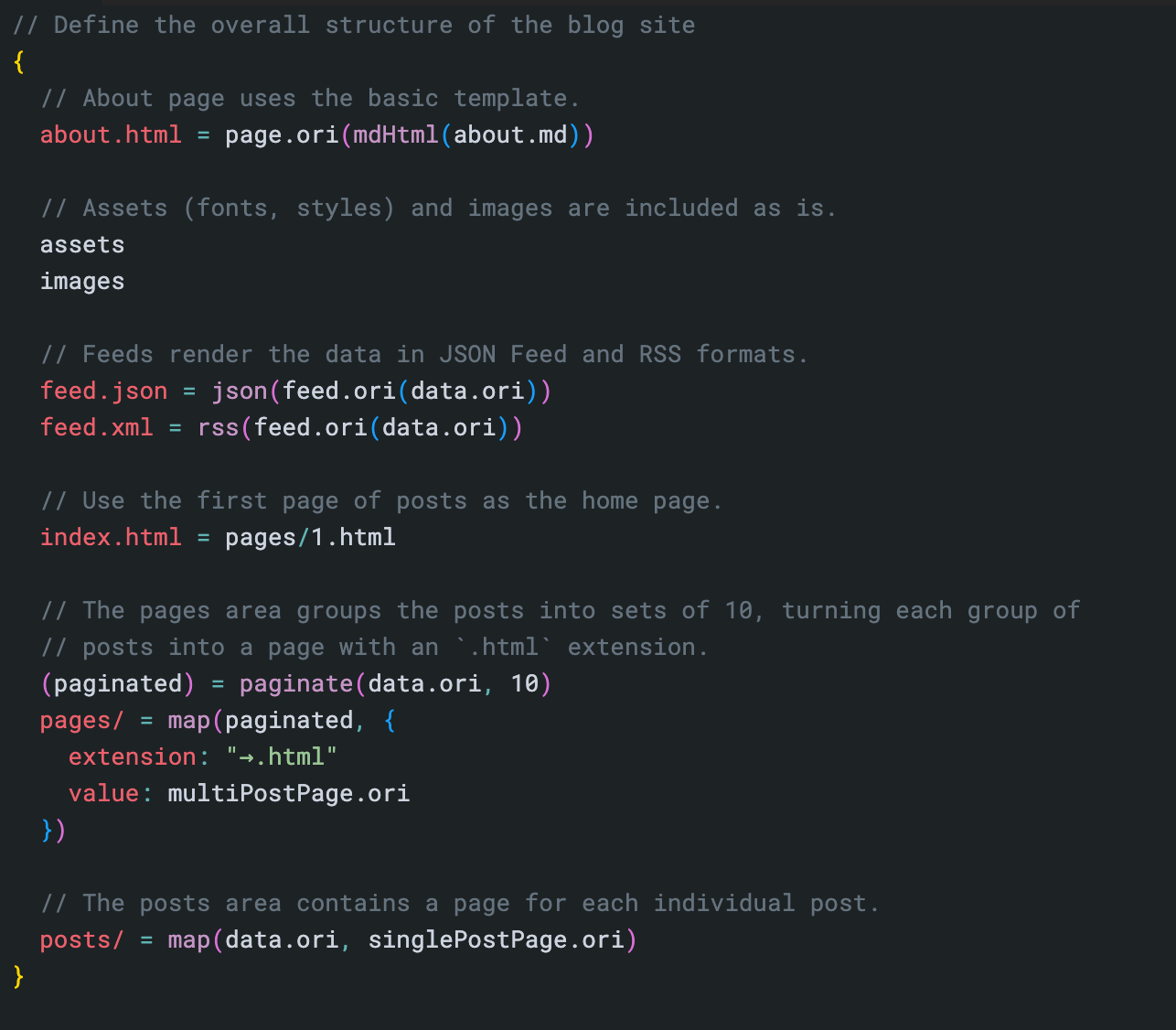
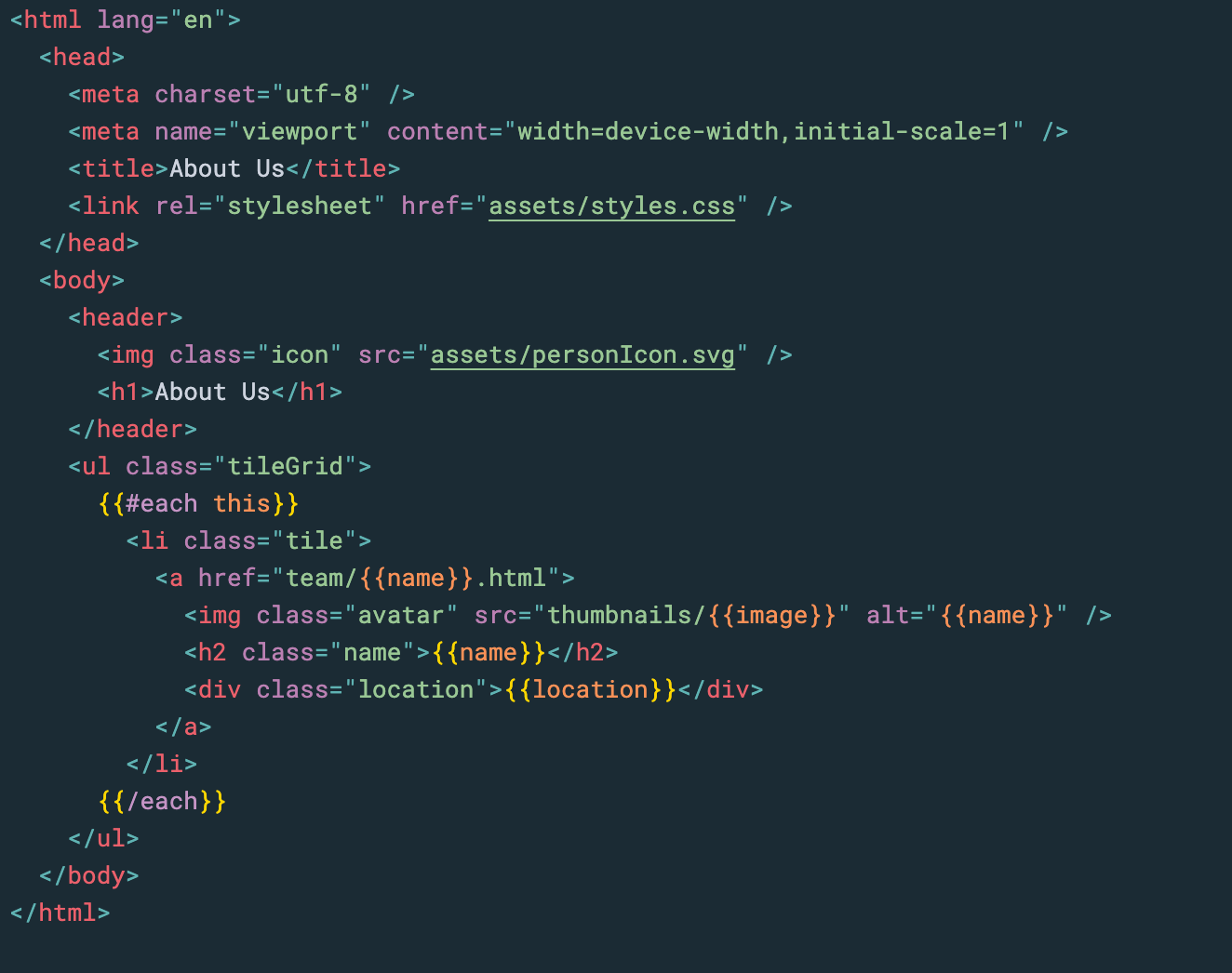
The Origami programming language complements HTML and CSS to let you define the structure of a site. You write formulas or expressions at roughly the level of complexity of spreadsheet formulas. These fully determine the site you get; nothing happens unless you ask for it.
The language is concise and powerful. The above screenshot shows the code for a sample influencer lifestyle blog. Those ~15 lines of code establish the basic site structure, and another 20 lines in other files prepare the raw content and produce the blog feed. That’s all that’s required to define a blog engine completely from scratch. For comparison, a typical blog engine might require much more code in its configuration file alone and be much harder to reason about.
A playtest is generally done as a video call. You outline your goals and then either go through an Origami tutorial or we work together to start something from scratch. At this stage of the language’s evolution, direct observation is extremely helpful. Some people find that prospect intimidating, but this is a playtest! We will test the language — no one will be testing you.
The Origami documentation is complete enough that a motivated person could potentially get up and running on their own, but the onboarding won’t be as easy as with an already well-established, mature language.
I am deeply touched by the warm response to my recent MomBoard: E-ink display for a parent with amnesia post. It got much more circulation on Mastodon that I usually get, and overnight someone posted it to Hacker News — where it shot to the #1 story. I discovered this after waking up and finding my inbox full of LinkedIn requests.
The post stayed on the HN home page for two full days, which stunned me because their story ranking algorithm heavily discounts stories over time. The story got 2000+ points, more than every other post on HN that day, beating out the day’s news that The Onion bought InfoWars.
In response, I received a number of emails from people with a parent or loved one in a similar situation and wondering whether I could make the MomBoard source code available.
That was a small challenge, as the project has more in common with a home-cooked meal than a finished product. I’d written the project for a tiny audience of family members and had taken the liberty of shortcuts that wouldn’t work for others, like hard-coding people’s names.
I’ve done my best to document the “recipe” for this project in the README. It’s long and complicated, and perhaps only useful as inspiration; we’ll see. Like most home recipes, people will want to adapt the recipe to their own tastes and situation.
Today marks two years since I first set up an e-ink display in my mom’s apartment to help her live on her own with amnesia. The display has worked extremely well during those two years, so I’m sharing the basic set-up in case others find it useful for similar situations.
Note: unless you have specific experience caring for someone who has amnesia but not dementia, please do not offer care suggestions.
The patient
In June 2022 the side-effects of a long surgery left my mom with permanent anterograde amnesia: she can no longer form new long-term memories. Memory isn’t just one neurological system, so very occasionally she will be able to remember certain types of things. But for the most part, if she hears or sees something, a few minutes later she will no longer remember it.
To medical professionals her condition looks a lot like dementia — amnesia is a common symptom of dementia — but she doesn’t have dementia. One difference is that (as I understand it) dementia is a progressive disease, while this amnesia is stable. There is no cure.
Someday I might post about the experience about caring for her, but for now I’ll just say that this type of amnesia is not something one should wish on one’s worst enemies.
Needs
My mom still lives on her own in an apartment. Because she cannot remember things, she goes through each day in a state of low-grade anxiety about where her grown children are and whether they are all right. She feels she hasn’t heard from any of us in a long time. This anxiety manifests as extremely frequent attempts to call or text us.
Paper notes and other forms of reminders didn’t seem to help, and would become out of date even if they weren’t misplaced. My siblings and I would call to let her know we were okay, but five minutes later she’d be back to being worried. She wasn’t in the habit of scrolling back through text messages, so once she’d read a message, it was immediately forgotten and effectively lost.
I thought some sort of unobtrusive, always-on device installed in her apartment might be able to show her notes written by my siblings and me.
Design goals
My goal was to find a display that:
Could stay on for months on end
Would let my siblings and I easily post short messages to it that would remain visible until replaced
Was large enough and easy enough to read without glasses
Required no interaction to wake or read and was relatively foolproof (touching it wouldn’t disrupt it)
Was resilient to network failures
Didn’t glow at nighttime
Didn’t require hardware hackery (I’m a software person)
Would boot directly into displaying messages (no interaction needed to start an app)
Was not enshittified with a subscription service or proprietary app store
Was reasonably affordable
Would not look out of place in a home
Device
Given the above design goals, I searched for a tablet-size electronic ink display with Wi-Fi connectivity and a decent web browser.
One device that seemed to fit my parameters was the BOOX Note Air2 Series. At the time it cost US$500, which is expensive but is still far cheaper than screens intended for use as commercial retail displays. It’s marketed as a note-taking device and ebook reader, but it also has a capable web browser. It’s big enough to read from a few feet away.
A critical question I couldn’t answer online was whether I’d be able to have the device automatically start its web browser and have that browser display a designated start page. Happily, when the device arrived I was able to confirm it could do both of those things.
The physical case of the Note Air2 looks reasonably nice and not particularly tech-y. The e-ink display is clear and legible; it refreshes quickly enough to not be distracting. By default the device’s backlight was turned on but I could turn it off.
I found a small metal stand to serve an easel for the display so that it felt more like a picture frame.
Web software
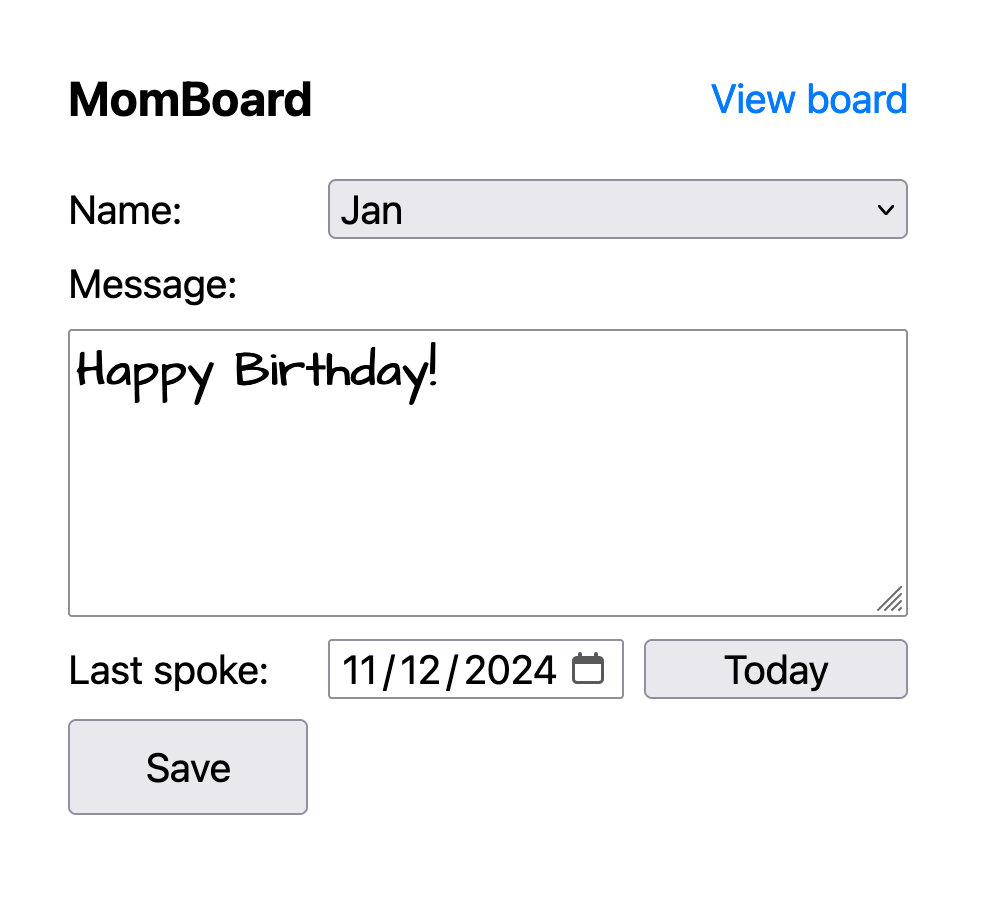
Since the physical device was satisfactory, the next step was writing a simple website that could drive the display. The site would have two pages:
A Board page showing the messages. The e-ink device would boot into showing this page. This is the only page my mom needed to see.
A Compose page my siblings and I write messages and save them to be displayed.
The device needed to run for months, and needed to be resilient in the case of network and service failures. At the same time, I also needed to be able to remotely update not only the messages being displayed, but the software displaying those messages.
With that in mind, I factored the Board page into an outer frame and an inner page:
The top-level outer frame acts as a thin shell around the inner page. At top of every hour, the outer frame reloads the inner page to pick up potential software changes. If the network is down and the inner page doesn’t reload, the frame just tries again an hour later. To maximize reliability, the outer frame has very little logic and no external dependencies.
The inner page actually displays the messages. Every 5 minutes it queries a simple web service for message data and displays the messages. The inner page contains a small amount of logic, but as few dependencies as possible.
Since it’s essentially impossible to debug anything that happens on the device, I made as much use of vanilla HTML and CSS as possible. I used a small amount of JavaScript but no framework or other libraries.
The Compose page presents a simple web form my siblings and I can use to compose and save a message. I designed the form to work well on a phone screen so that we can write messages when we’re out and about. A small web app manifest lets us save the Compose page to a phone’s home screen as an icon for quick access.
The whole site is tiny, entails no build process, and with the exception of the service (below) is just static files.
Visual design
I was concerned about the possibility of e-ink burn-in, so the Board page randomly changes which message appears where. Other visual elements like the date and time alternate from side to side, with the intention that no single pixel is always on.
To style the note text I chose the free Architect’s Daughter font for a handwritten feel. This font works well on the e-ink display. Labels are displayed in Open Sans.
One small challenge was maximizing the size of the message text. Sometimes a message is just a word or two; other times it might be several sentences. A single font size can’t accommodate such a wide range of text content. I couldn’t find a pure CSS way to automatically maximize font size so that a text element with word wrapping would display without clipping.
I ended up writing a small JavaScript function to maximize font size: it makes the text invisible (via CSS visibility: hidden), tries displaying the text at a very large size, and then tries successively smaller font sizes until it finds a size that lets all the text fit. It then makes the text visible again.
Service
Just a tiny amount of text data is necessary to drive the display, so I was happy to find the minimalist JsonStorage service that was perfect for this project. A single JSON object stores the text and metadata for the current set of messages. The Compose page can save to the service with a POST request, and the Board page can retrieve the data with a GET.
The service has a free tier that I started with, but I liked the service so much that I eventually paid for a $1/month basic tier. (It appears that tier is now $5/month.)
Trial and installation
I spent a couple of weeks working on the software and letting it run for long periods of time. I was pleasantly surprised that the Boox display worked as well as it did and seemed to stay up indefinitely.
I brought the display over to my mom’s apartment on November 12, 2022, turned it on, joined it to her Wi-Fi, and rebooted it to confirm everything worked in the new environment.
I thought the bathroom counter might be a good place for it, but my mom thought she’d rather have it in her bedroom, so we found a home for it on a windowsill.
My mom was happy with the display right away.
Retrospective
Despite her amnesia, my mom came to remember that this display exists and what it’s for. She looks forward to seeing updates from her children on it.
If we tell her about something that’s coming up, she often asks whether we’ve already put that event on the MomBoard. On the flip side, we have to be careful to keep it up to date; if we fail to take down a message that no longer applies, it confuses her.
Looking back, the display is essentially the only intervention of any kind we’ve tried that’s actually been successful at improving her quality of life (and ours). One reason it’s worked so well is that it didn’t require her to learn anything new. Without the ability to remember new things, it’s virtually impossible for her to learn a new skill or to form new habits.
The device’s reliability has surpassed my expectations. There was one period where the device seemed to stop working, but I traced the problem to a faulty Wi-Fi hub; after that was replaced, it’s worked flawlessly since. For my part, keeping the software as simple as possible and sticking to vanilla web technologies surely helped avoid bugs.
The display still looks great, and it still displays messages day in and day out.
If you want to try to set up something similar to what I describe here, I’m happy to answer technical questions or share advice.
I was able retire an old #Heroku site by copying the content to a completely #static #website. Instead of resurrecting the source project and rewriting it, I used the #WebOrigami crawl command to retrieve the static files.
The @crawl picked up all but a few exotically-referenced resources that I copied over by hand. I dropped it all on Netlify. Some pages didn’t have an .html extension, so I added a small Netlify config to serve those as HTML. Then I pointed the old domain at the new site: Done!
Retiring this server as a static site reduces my monthly cost for it from $7/month to $0. The site’s for an old startup company but includes documentation for a web components library that I want to leave available.
If you’d like help retiring a site, let me know and I’ll see if I can assist.
The basic site auditing tool in #WebOrigami can work against a site defined in many ways: a data file, files in the file system, an Origami program — or a live #website running in production.
In the video I show an audit of the unbelievably massive Space Jam. For a site with 350+ handwritten HTML files, it contains surprisingly few broken internal links.
A simple protocol lets you make the contents of your #smallweb / #indieweb site more fully discoverable and explorable by interested users. This can also let site A see what resources site B offers.
I’ve been working on this in the spirit of the web’s simple, venerable, and immensely valuable View Source facility. View Source just lets you view a single HTML page; the web lacks a standard equivalent of a directory listing for a given route. This aims to fill that gap.
I made a short video walking through how I generate OpenGraph images for the pages on my blog using Origami.
This video is an experiment. It takes me ages to create polished documentation or videos — and that’s discouraged me from creating anything at all! I thought I’d try recording a video with only minimal rehearsal and no editing and see if this kind of thing can fill the gap until I can produce something better.
To demonstrate that Origami is a good language for building #smallweb / #indieweb blogs, I built a fun sample blog reenvisioning Henry David Thoreau has a modern influencer with a lifestyle blog about off-grid living.
Creating a site in Origami is completely different than creating a site in any other tool I know of.
Origami isn’t a blog engine or framework, just like Microsoft Excel isn’t an invoicing or expense reporting framework. Excel is a general tool that transforms and aggregates numbers and text in tables. Origami is a general tool that transforms and aggregates data and content in trees.
So this project isn’t configuring a blog tool — it’s defining what a blog is from scratch. The source is endlessly malleable, and you can readily change what gets produced to achieve a wide variety of results.
To build in Origami, think about the starting tree of content you’ll write or gather by hand, and the final tree of resources in your running site. Step by step, you transform the former into the latter.
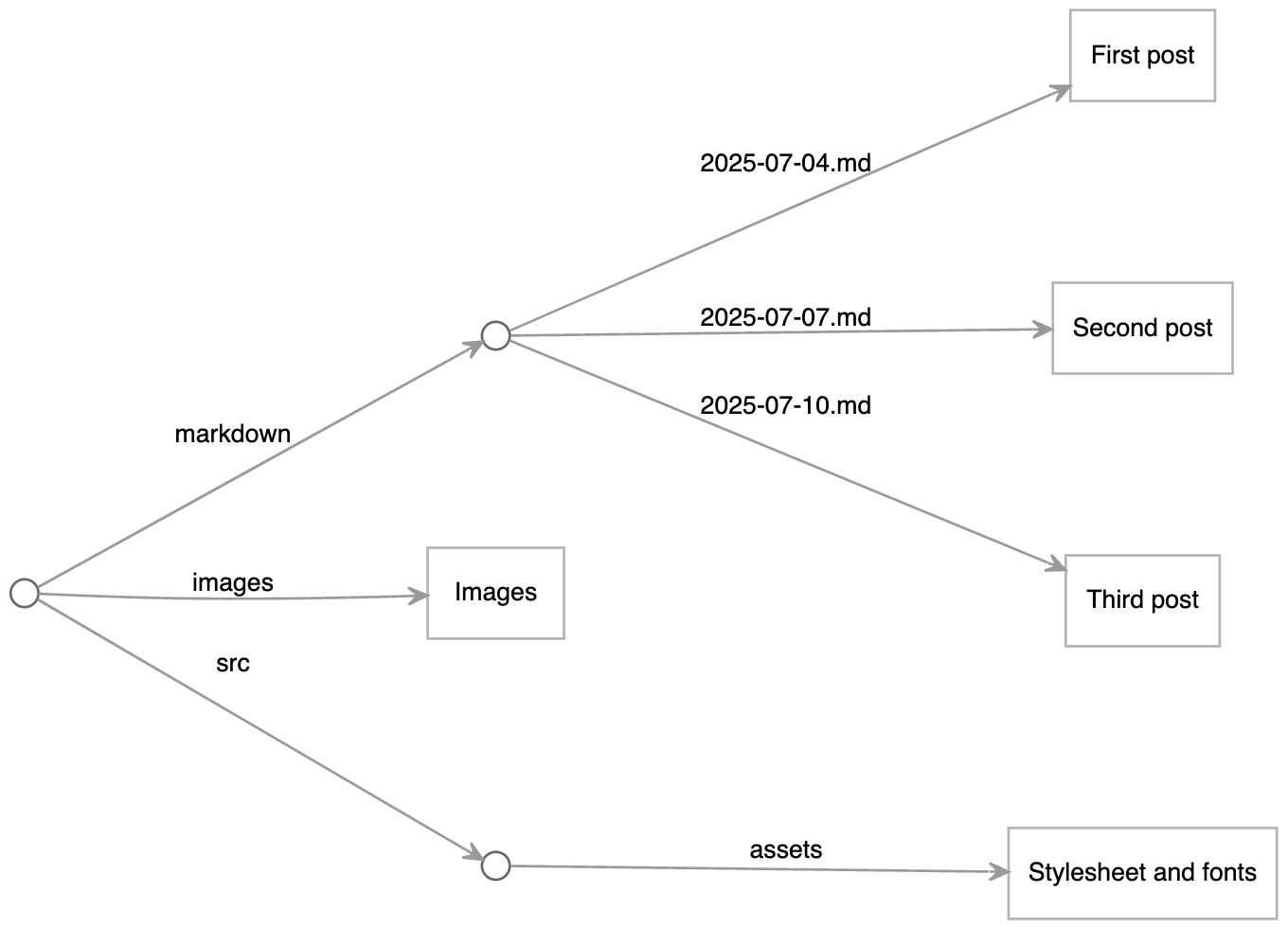
For a blog you might start with, say, a markdown folder containing markdown posts, an images folder for photos, and an assets folder for stylesheets.
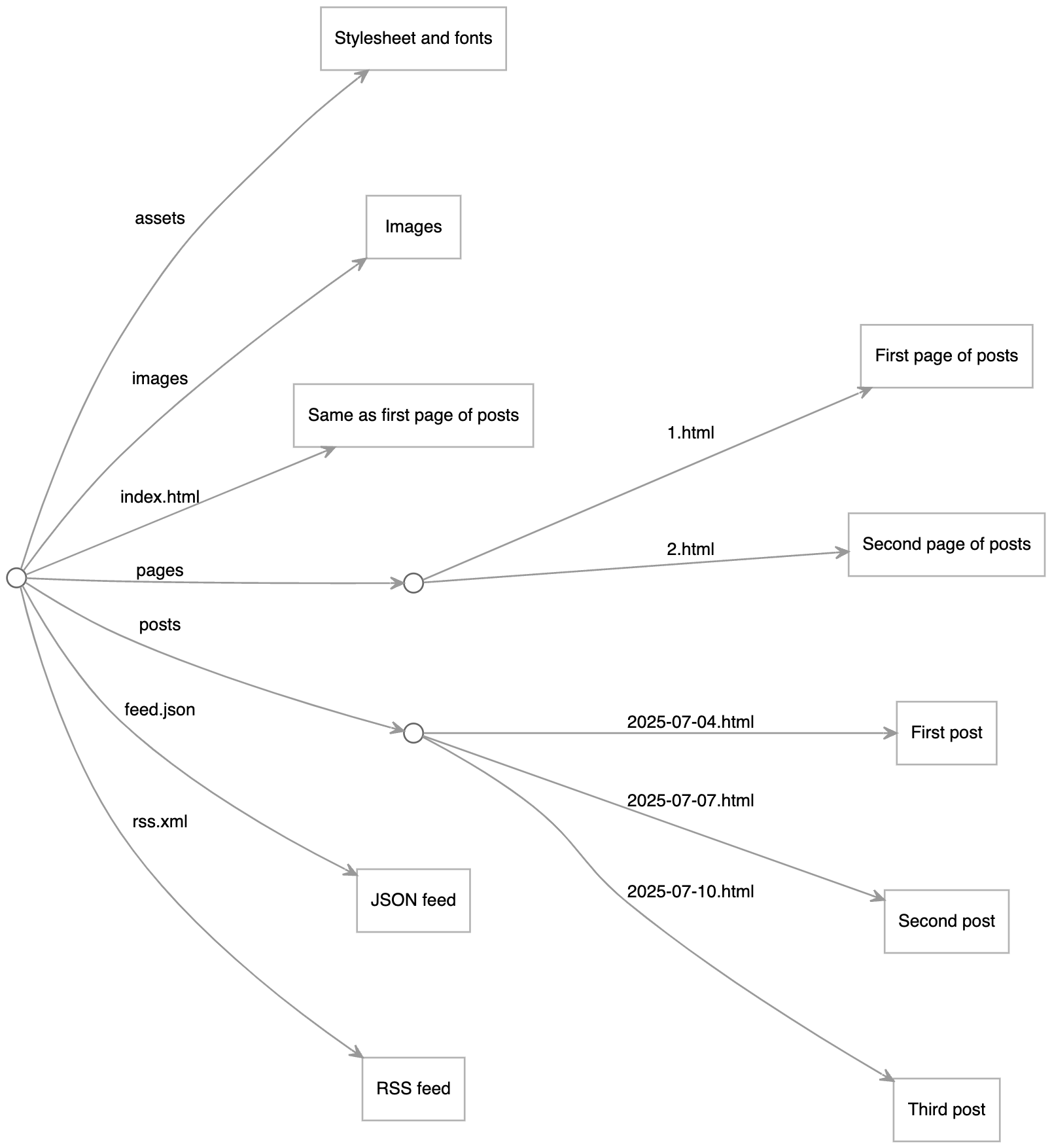
The final resource tree comprises the images and assets as is, plus generated pages for individual posts, list pages, and feeds.
To generate individual pages you can use a template language. Origami has a nice one built in; you can use others.
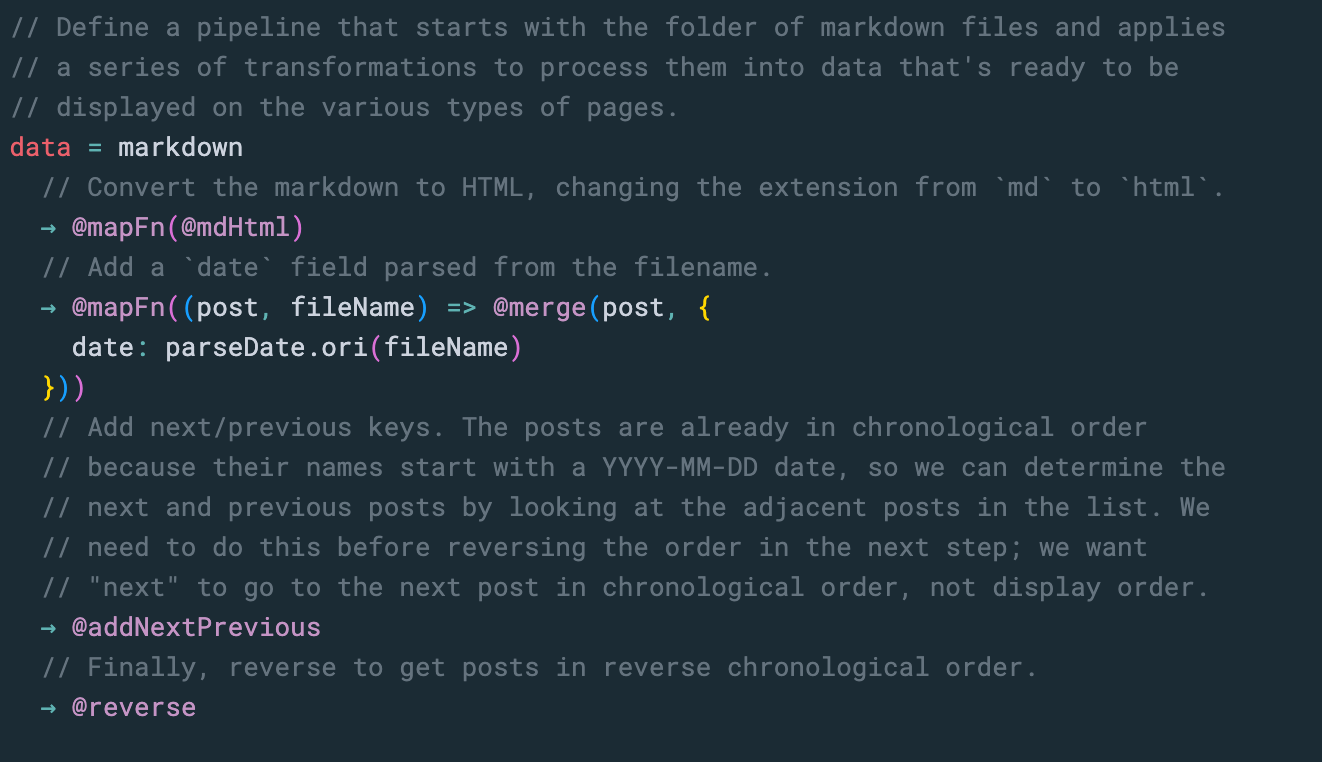
But the real magic is writing formulas to process a pile of content at once, like a pipeline that transforms markdown to HTML, calculates data, and sorts the posts to prepare them for rendering.
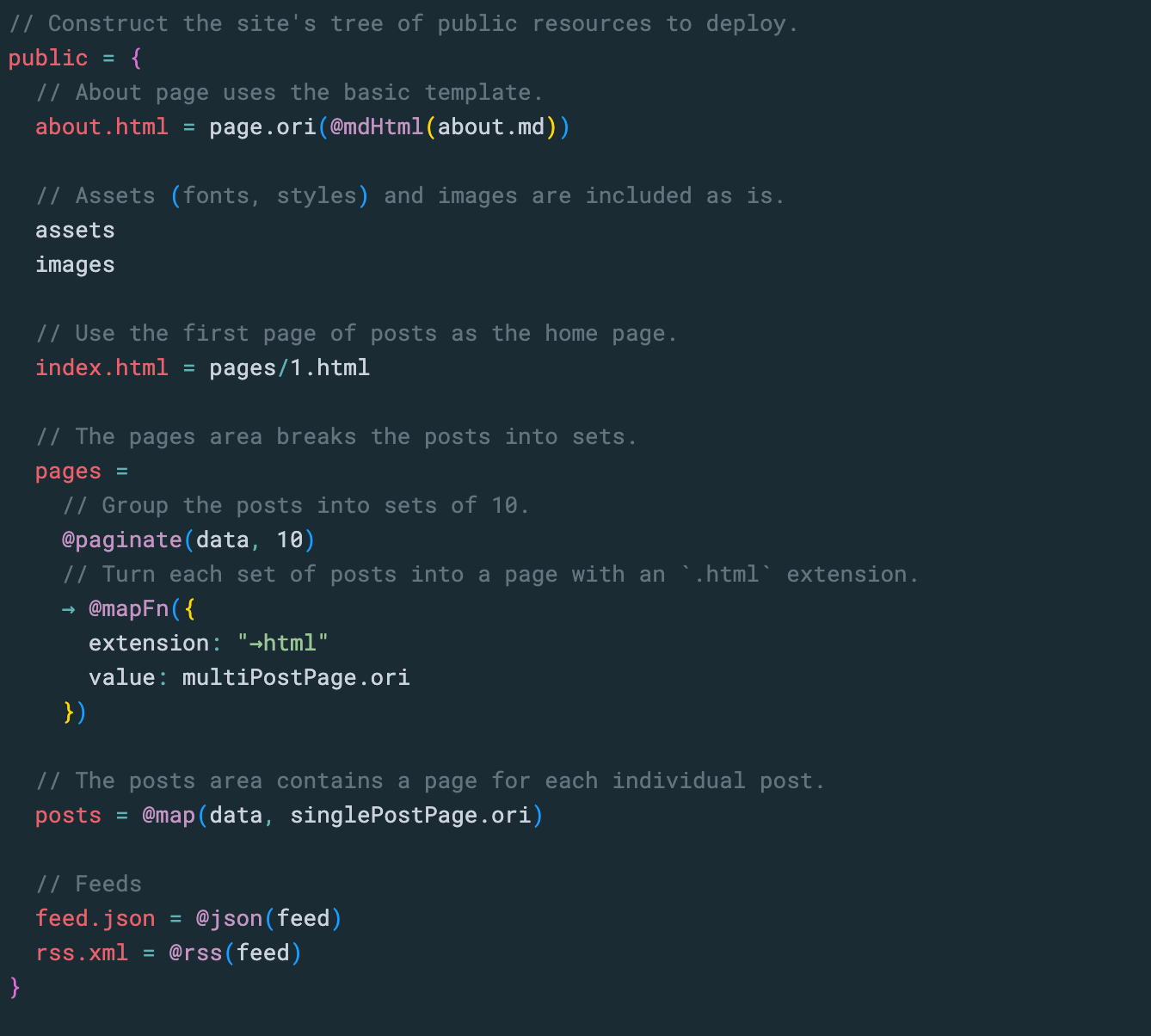
Or a compact definition of the entire public portion of the site:
This Origami program generates the full tree of the resources for your blog, which you can browse immediately. The Origami runtime only does the work to generate a page when you ask for it.
The same Origami program can also produce a complete build folder with all your site files. Deploy those on a static web server or have a service do a build whenever you update your project.
Each month this year I’m trying to post a sample website written in Origami, a declarative programming language at the level of #HTML and #CSS for defining websites. This month’s sample is Aventour Expeditions, a site for an outdoor travel company.
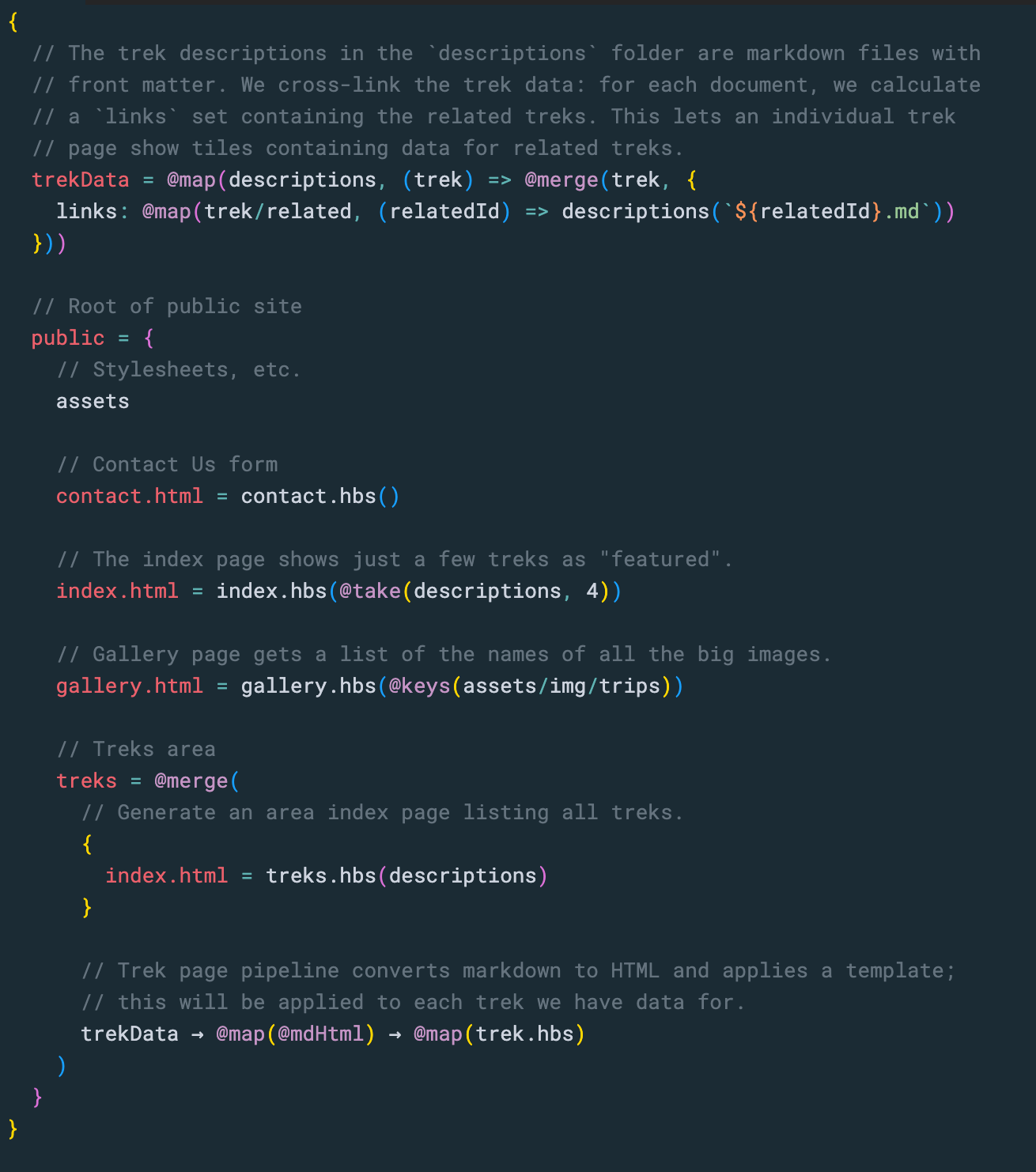
It’s easy to have Origami call other template languages, so for this sample I used the Handlebars template language to turn markup and data into HTML.
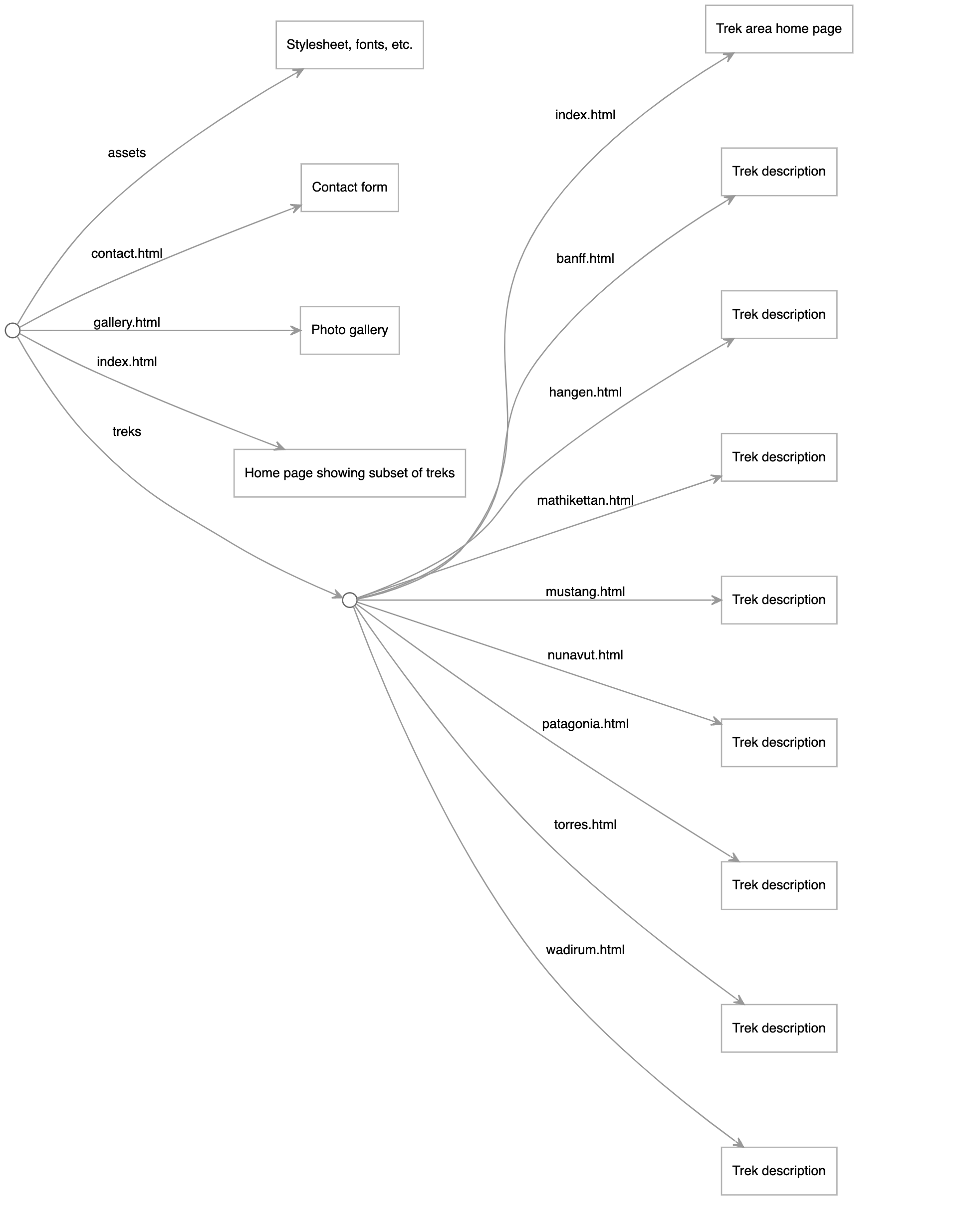
It took just a few lines of Origami code to define the structure of the site and indicate which Handlebars template should be used to create which pages. For this outdoor travel example, Origami makes it very, very easy to:
Create a web page for trek described in markup with front matter.
Create index pages showing cards for a set of treks.
Create a gallery page showing each image in a folder. Origami makes it very easy to pass a Handlebars gallery template the list of image file names, which the template can turn into img tags and links.
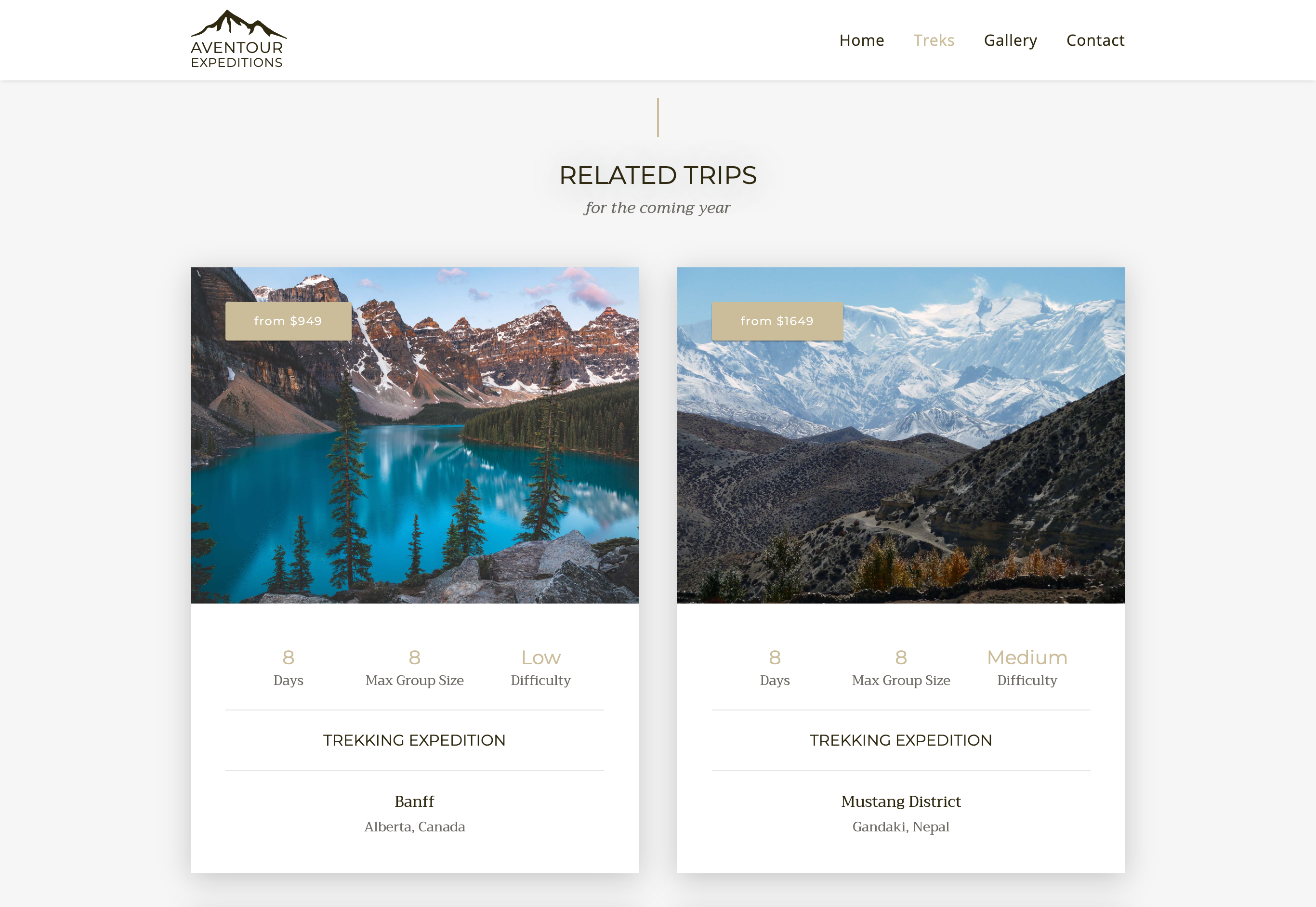
Origami also made it easy to cross-link the data for each trek with related treks. That allows the page for one trek to show cards links to related treks.
Aside: modern HTML and CSS are soooo much better than the past. I based the trekking site on a WordPress template whose design I liked but whose HTML/CSS was ridiculously complex and burdened with tons of JavaScript for trivial things.
Rewriting slashed the size of the pages. For the home page:
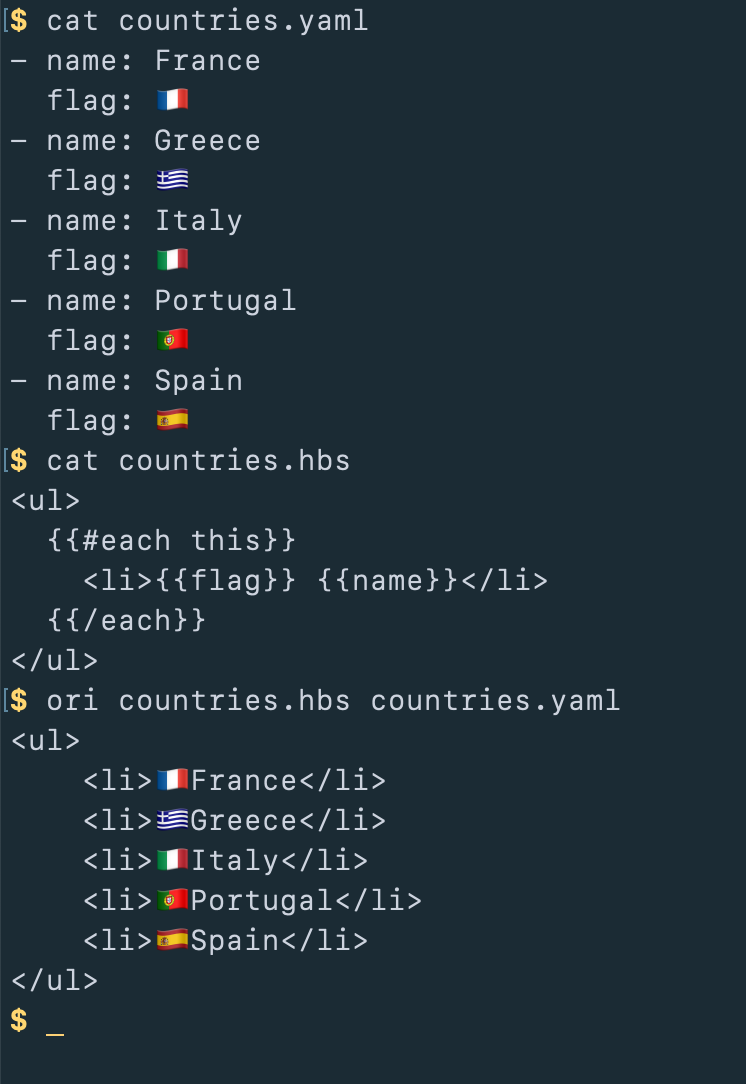
So a handler can load a .hbs file as a function that applies a Handlebars template, then apply that in the command line.
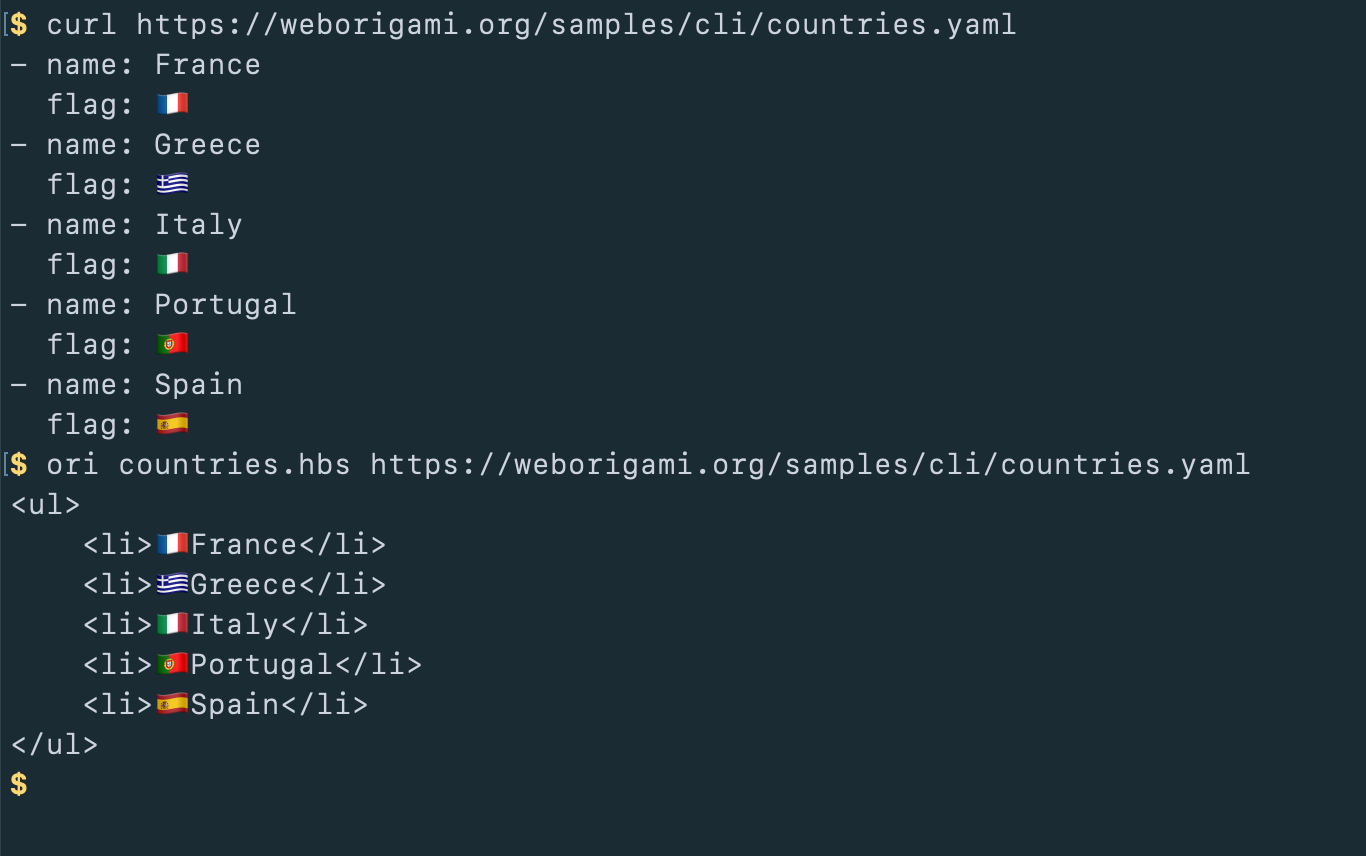
Origami can resolve pretty much anything — JSON/YAML files, files with front matter, entire folder trees, a ZIP file, whatever — to an object your Handlebars template can operate on.
You can even write a one-liner that fetches data from a server and applies a template to it.
Applying a Handlebars template to a file system folder lets you, e.g., generate an HTML index page with links to all the HTML pages in the folder.
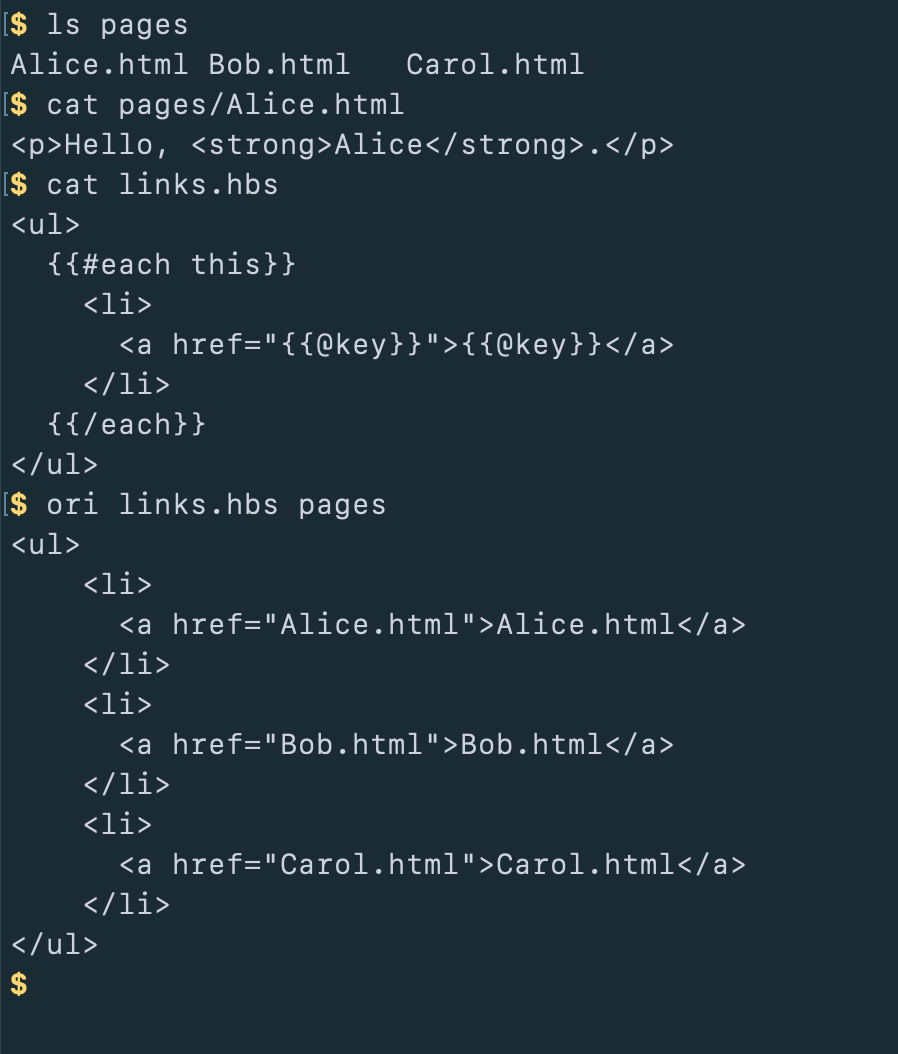
If one Handlebars template references another template (a “partial”), Origami resolves that reference for you. If you reference bold, it will look for a template named bold.hbs and use that.
This lets you decompose templates for complex results without the usual overhead of manually loading those templates and passing them as Handlebars configuration.
Origami itself is a powerful template language, but you might prefer Handlebars or some other template language. You can use Origami to define the overall structure of your site, then use Handlebars/etc. to turn data from anything into HTML.
It was easy to rewrite the Origami “About Us” sample site using Handlebars.
Suppose you want a photo blog that’s not on Tumblr or Instagram. Maybe you don’t like being sold, or want to draw outside the lines, or want photos as part of your own site. What would a #smallweb alternative look like that let you post a photo and caption from your phone?
I made a proof-of-concept street art photo blog that supports this on-phone flow: 1) snap a photo and set a caption, 2) save the photo to Google Drive via Files, 3) trigger a rebuild via the browser, 4) see the new photo on your own site.
Google Drive is hardly #indieweb, but look beyond “corporate = bad” and consider the nature of the relationship. They provide a commodity service: you pay them, they store your files. Those files are a medium of exchange. If (when?) Google screws around, you can easily move the files to a different storage provider. Switching costs for hosted platforms like Tumblr or Instagram are far higher.
All storage services provide a proprietary API to enable unique features and faster service… but also to force you to write to that API and make your own code a switching cost. But most of what you want from storage is just an easy way to: 1) list directories, 2) read a whole file, and (maybe) 3) save a whole file.
This interface lets small storage drivers wrap the proprietary APIs; switching providers is just a matter of switching drivers.
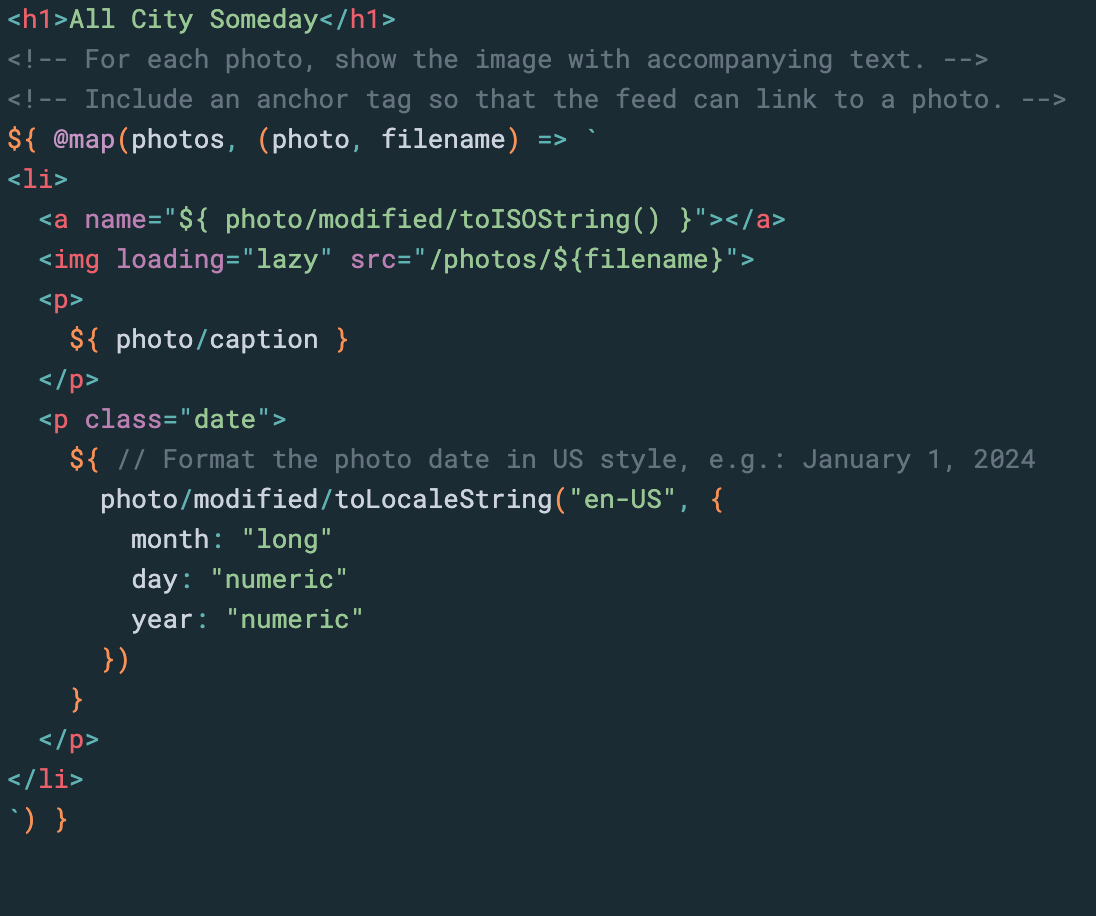
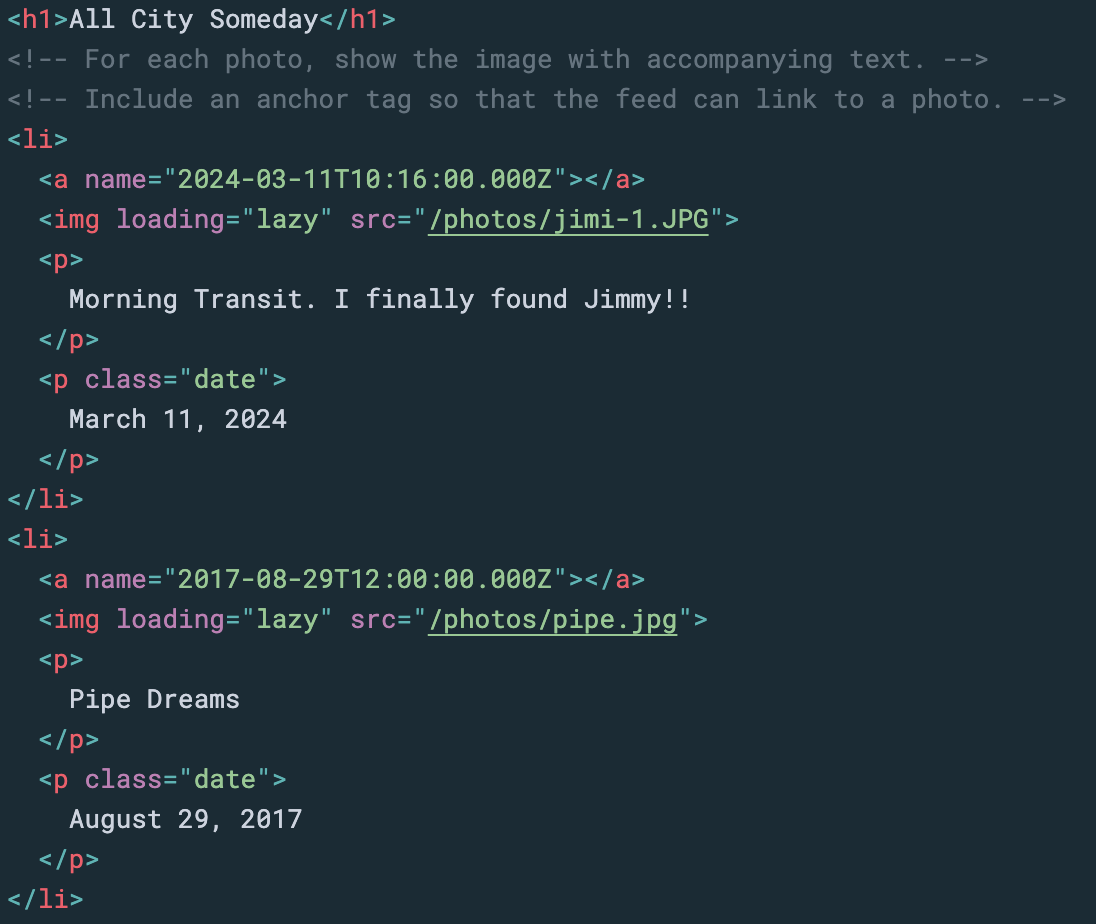
The Origami language can use such a driver to read images out of Google Drive and create a static, deployable site. Origami templates also understand that interface, so you can make a template that directly maps a folder’s photos to HTML <img> tags with dates and captions. 🎉
One significant hurdle: obtaining a Google API credential file. OMG figuring out any kind of auth on Google, Azure, or AWS is like wandering through a maze of twisty little passages, all alike. It’s also theoretically possible to use Google Cloud Pub/Sub to automatically trigger a site rebuild whenever a photo is added to Google Drive, but dang that looks complicated. Maybe some other day.
Standards like Exif (for photo captions and dates) make amazing things possible. They’re there for everyone to use — if a corp isn’t trying to cage you in their silo.
iOS/macOS Photos lets you edit the caption and save it in the photo so this photo blog can extract it. ✅
Google Photos lets you enter a caption but AFAICT saves it in a proprietary database instead of the photo file. Shame on them. ❌
The code for this photo blog is small: HTML + CSS + about 40 lines of Origami code. That includes defining RSS and JSON feeds. 😃
If I ever needed to switch storage providers, I’d just have to update the 3 lines of code that authenticate with Google and get a reference to the Drive folder. Everything else would stay the same.
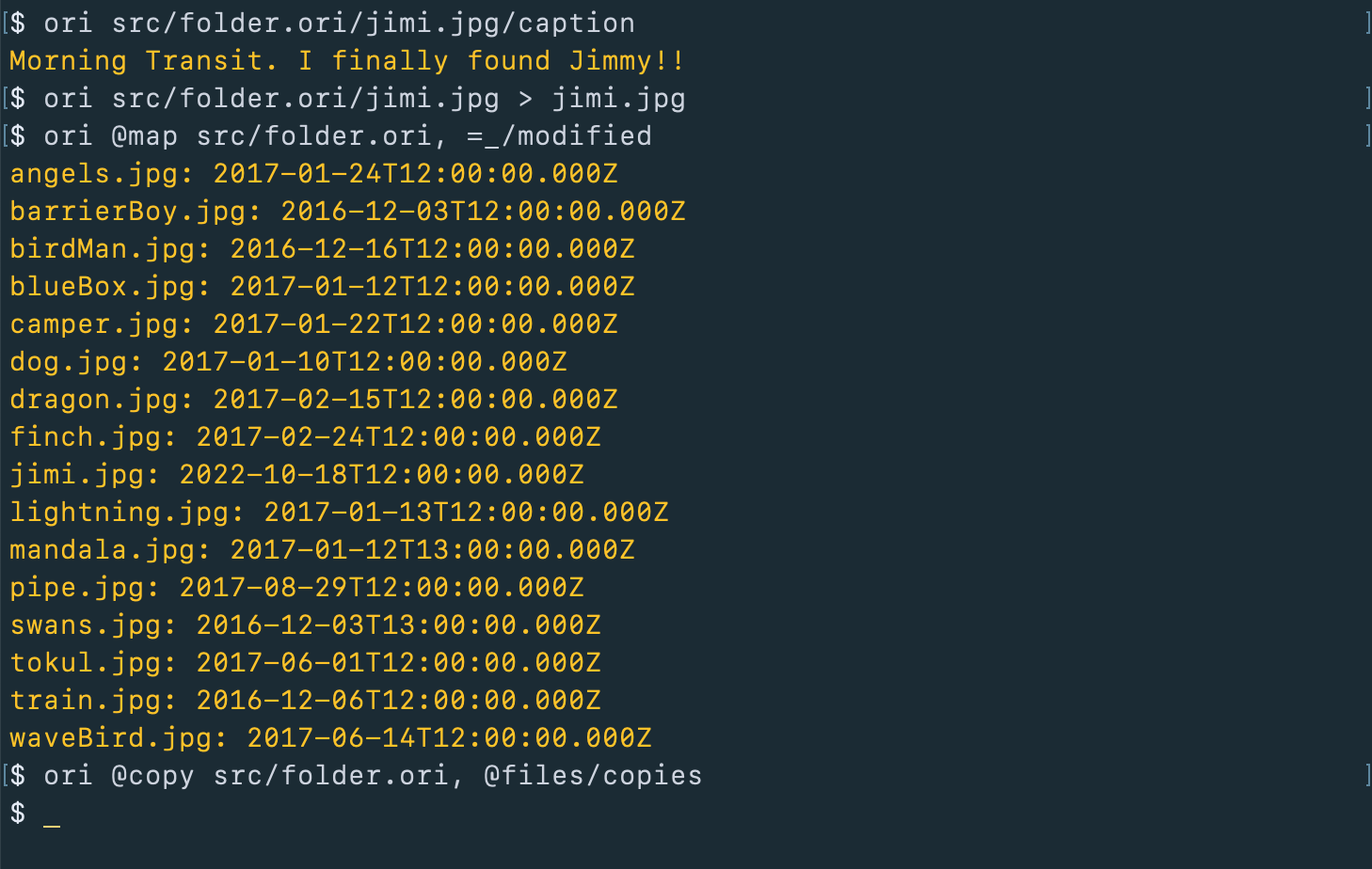
Abstracting away storage doesn’t just give you an interesting way to build a site, it also opens up general-purpose terminal access so you can:
Extract the caption from a specific photo on Google Drive
Extract a specific file from Google Drive
Extract the dates from all the photos
Copy all the files from Google Drive to the local machine
Design notes:
It was fun to play with #CSS blur, text-shadow, and -webkit-text-stroke for a graffiti heading that’s just plain text! May also be the first time I’ve ever used magenta.
I was able to auto-size the header width to be roughly as wide as the photos by playing with values for font-size: clamp(…).
The fonts are so different from the stock fonts that any font swap was really jarring, so I forced early loading of the small font files and used font-display: block.
In the summer of 2023, I walked for a month from the Pacific Coast to the Sea of Japan. I crossed steep mountains including Mt. Fuji, portions of the Southern Alps, the Yatsugatake range, the Northern Alps, and the Shio no Michi Trail. In between, I walked through cities, towns, and rural areas. The hike was a substantial challenge but also a fun adventure.
Before reading it I hadn’t appreciated that EPUB files are just ZIP files with a particular folder structure and some book data. In retrospect that makes sense, but for me that single insight demystified the entire prospect of creating an ebook. It’s just a small bundle of files, mostly HTML, and some metadata.
You can use apps to make an ebook, but I wanted to build one more directly. Since the Origami website definition language is great at processing trees of content (like a folder of text and images) into new forms, I realized it could easily generate an ebook in EPUB format.
It wasn’t hard to write an Origami program to generate files in the required folder structure, and then it was just a matter of zipping it up.
Which left the question: what material could I turn into a book?
JamesG posted a good list of ideas for things people can do on their website. Facundo Olano expanded on that to suggest adding EPUB downloads for your blog or subsets of it. Their posts made me realize my own hike posts might make an interesting sample book.
During the hike I’d kept a travel diary in markdown with photos, so it was fairly easy to add a cover image, an introduction, and some metadata. Voilà: a book!
It may seem silly, but packaging something as a “book” feels weightier. Simply seeing the cover art in my ebook library alongside purchased novels was thrilling, as was opening up the book and paging through it. It felt like that day in third grade when a teacher had us bind illustrated stories into books and the school librarian put them on a library shelf. 📚
Try making an ebook — about anything — and you’ll feel the same thrill.
The site’s structure is defined in a single file in the Origami site design language that turns the sample artwork images and data into a gallery home page and a separate page for each print.
I built this to try out Snipcart, a web service for adding a shopping cart to a static site. They seem to charge lower fees for this service than the larger site hosting platforms, and it was trivial to add the shopping cart with a few HTML attributes. I love that their approach leaves you in control of the rest of your site. That said, I haven’t signed up to use Snipcart to actually complete financial transactions; if you’re interested in Snipcart, investigate it carefully.
I also used this store site to experiment with the new web View Transitions API. I was able to create a zoom effect that works across page navigations (!) which is completely nuts. Caveats: currently in Chrome/Edge/Opera only; it was hard to figure out how to do what I wanted; Chrome sometimes shows a white flash before the zoom-out animation. Still, I’m excited to see these effects coming to simple multi-page sites.
Internet archives are amazing and under-appreciated.
I searched a #Usenet archive for a program I’d written decades ago in high school: an interpreter for the Karel programming language for use in intro CS classes. Because wonderful people have maintained those archives for many years, I was able to find my program 40 years after I wrote it. https://www.usenetarchives.com/view.php?id=net.sources&mid=PDI5OUBzcG9jay5VVUNQPg
It’s hard to describe what it’s like to see that #C code again now. (Although I’m frankly appalled that teenage me didn’t put curly braces around one-line if clauses and for loops.)
I downloaded the source and was delighted that the ancient #Unix shell script to extract the code still runs just fine in bash. (It would take much more time to actually get the program itself to work again.) I posted the source on GitHub: https://github.com/JanMiksovsky/karel.
40 years from now, which is more likely to still exist: the USENET archive version, or the GitHub version? 🤔 I’m betting the former.
When considering modern web development, I keep two images in mind.
This factory image captures how many devs approach creating websites: constructing an enormous, gleaming, automated system that can produce complex artifacts on a massive scale.
In contrast, an individual artisan working in a studio directly creates something simple but useful using their own hands and understandable tools. To me this second image captures the #smallweb/#indieweb spirit.
Factories aren’t always bad and artisans aren’t always good, but many devs can’t conceive of building anything without first making a big factory. “You’re creating that pot by hand?? Why, a gleaming pot factory could make a million pots a day!”
That’s ridiculous. A factory — even one magically built for you — can easily become a monstrosity you don’t understand but have to maintain. In many cases simple tools produce better results than a factory. And some of us like making things by hand!
The Origami language gives web creators functions for making parts of web sites in the same way a spreadsheet offers functions for crunching numbers: give a function some input, get something useful back.
Case in point: every so often I want a web page to show a screenshot of another web page. Puppeteer is great for that but cumbersome to set up, so I made screenshot functions: give them HTML or a URL, get back an image.
I used this to make a new Examples page on the Origami docs site. A build script uses the screenshot function to take pictures of each sample URL, producing a virtual folder of images that get saved as real images for deployment. This will make it easy to add new samples or update the screenshots as the sample sites evolve.
I enjoy videos of people showing off small homes they’ve built or van conversions they’ve done. The person shows off their craftwork, describes goals and trade-offs, recommends tools/components/techniques, and shares lessons learned. It makes building something feel approachable and can inspire people to try it themselves.
I’d love to see #smallweb/#indieweb creators do the same with #SmallWebBuild videos. Here’s my first.
Using small home and van build videos as models, the following could make for good #SmallWebBuild videos:
Introduce yourself, what the site is about, and why you made it.
Link to your site.
Show the site’s main features as a visitor experiences them.
Then describe some key points about how you built the site.
Describe decisions, trade-offs, challenges, or lessons learned.
Link to your code if it’s open source.
Link to tools/components/techniques you’d recommend. If their creators are on your platform, tag them.
Keep it short! You’re trying to inspire, not provide a how-to guide. Those are also useful but address a separate goal.
Keep the video production values simple. You’re more likely to actually finish the video, and a no-frills style reinforces the message that small sites don’t require years of experience, a huge team, or a big budget.
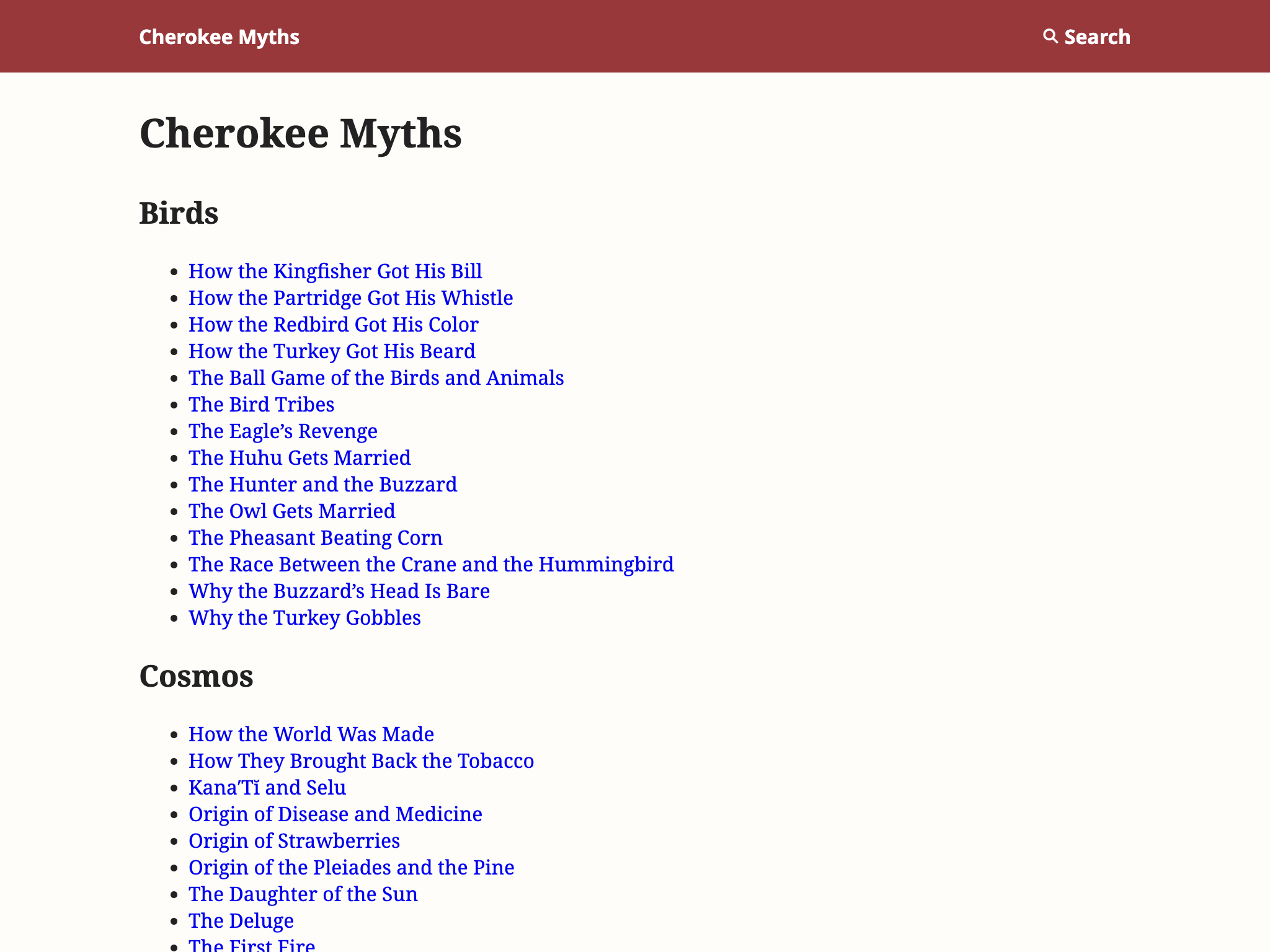
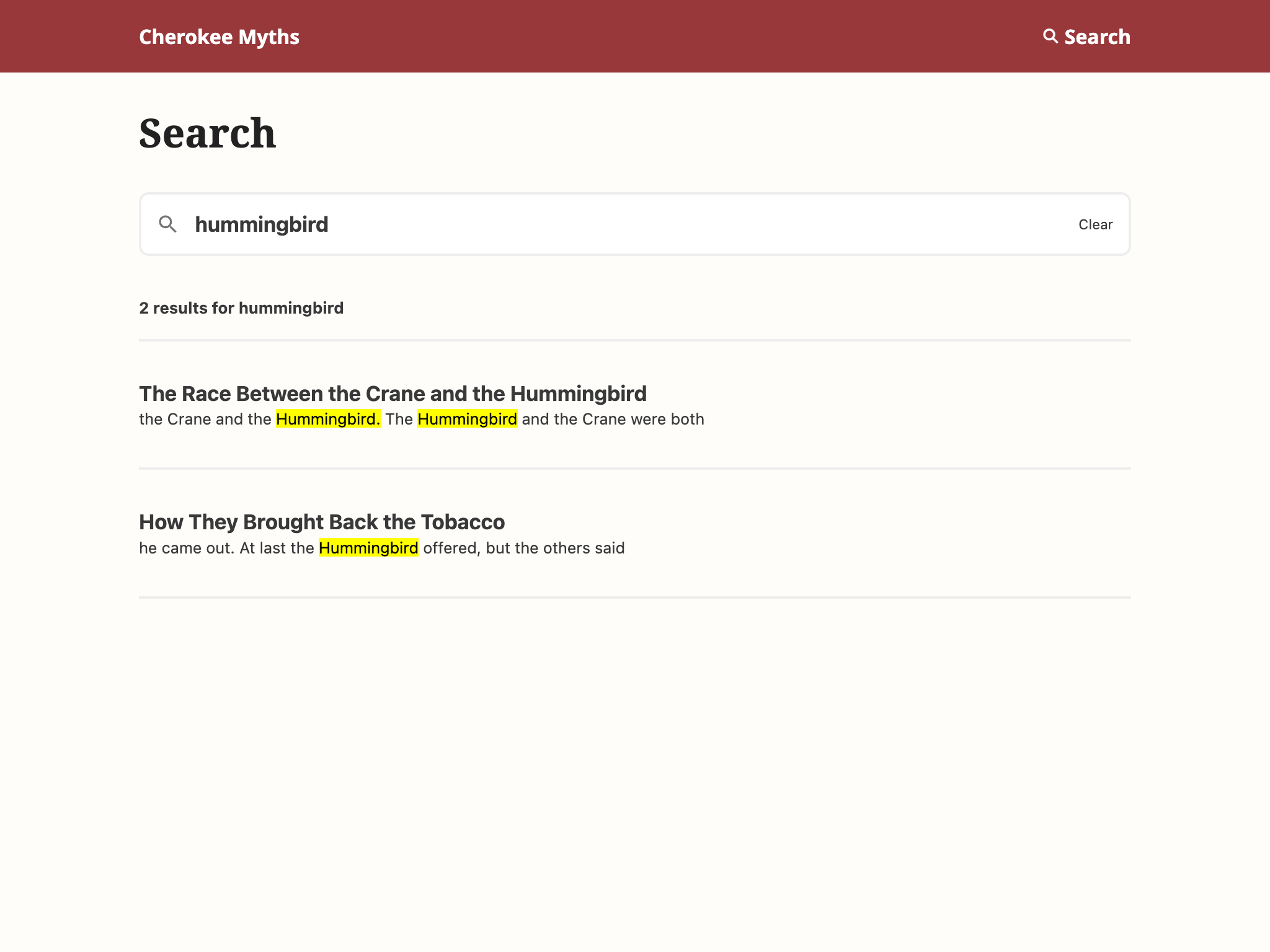
I built a sample Cherokee Myths site to explore how easy it is to create a static site in Origami that includes a generated table of contents and full-text search. I’m happy with how the site turned out.
As described in the site source, the site’s overall structure is defined in a single concise Origami file that orchestrates the creation of the table of contents on the home page, the generation of search indexes, and the processing of the tree of markdown content into HTML.
The tree of stories is flattened by a template to create the table of contents, and that same tree is also fed to a great tool called Pagefind to generate search indexes to allow full-text search on the static site.
Using public domain content for this sample was way more interesting than lorem ipsum text, and the Cherokee myths have a distinctly different mood than Greek myths or Aesop’s fables. The tale of the The Race Between the Crane and the Hummingbird did not end the way I’d expected.
This sample also gave me a chance to place with two recent CSS additions: text-wrap: balance so that long headings end up with lines roughly equal in length (instead of a long line followed by an orphaned word), and initial-letter to add a drop cap at the start of the story text.
Writing about the incompleteness of HTML/CSS/JS has helped me reframe my Origami language as a way to complement those native web languages.
People with some experience with HTML and CSS (but maybe not JS) have a world of ideas to share but may struggle with those missing platform pieces. Origami is a small language to round out the standard ones so people can make even cooler sites, especially small and independent sites.
The Origami language is small and focused on common web tasks. I take inspiration from the core W3C principle of the Rule of Least Power: choose the least powerful programming language for a given purpose.
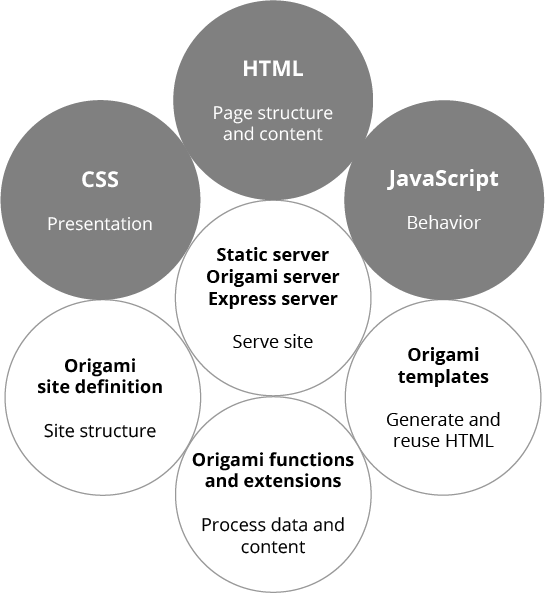
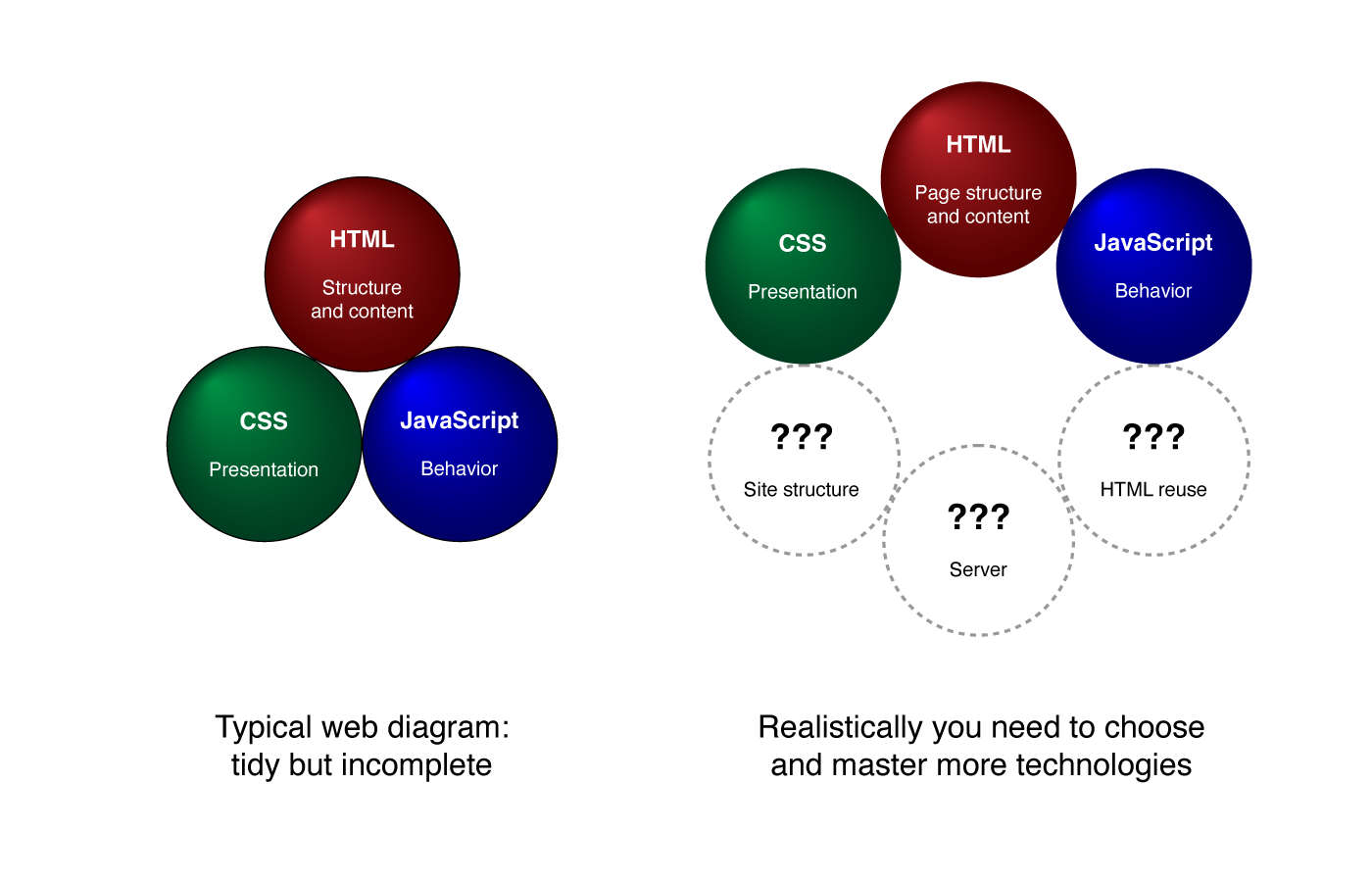
I see so many web platform diagrams that represent HTML/CSS/JS in a tidy, complete arrangement that suggests those are everything you need to know — when in reality those only let you define what happens in individual pages. A more realistic diagram would be incomplete! You’re going to need to choose and master additional technologies to create a coherent, functional site.
Even the simplest possible static site requires site structure (organizing the files into a folder hierarchy) and a server that can respond to web requests with those files. A non-trivial site generally also requires some way to reuse HTML across pages. Where is all that represented in the first diagram?
JavaScript developers will happily explain that their preferred language can be used for all those purposes via Node, so for them the first diagram is actually complete. That’s great for them! (I use Node too.)
But many people don’t want to learn JavaScript or find it too difficult, and for basic sites it’s massive overkill. Moreover, the diagram on the left suggests you can’t build a page without JavaScript, but I think JavaScript on the front end should be used sparingly.
I wish it were possible to create more complex sites just with HTML and CSS — but any aspiring web author learning to create a site that way quickly finds some very common task that’s impossible in plain HTML and CSS.
Author: How do I make my nav bars do that thing all nav bars do: where it shows the link to the current page differently so my user knows where they are? Web: Ah, yes, you want to do that! But you cannot. The browser certainly has all that information necessary to do that for you — you might have even been intrigued by the :local-link CSS property. That does just what you want! But no browser supports it.
Author: I want an Articles index page that links to all the articles I wrote in the /articles folder, and I want my Gallery page to show all the photos I have in the /photos folder. Web: Sorry, HTML just deals with what goes on a page. We have heard about these “folders” you’re talking about. They sound very popular! Not our thing, though.
Author: I want my blog post pages to have links to the next post and the previous post. Web: HTML defines what goes in a single page; there’s no way to represent a set of pages or interrelationships like ordering, much less reflect those relationships in a page. Think of HTML as an exciting “Build your own adventure”: you can do whatever you want — by hand!
Author: I want all the pages in my Products area to have the same layout, with a product name, photo, and description. I don’t want to have to repeat all the HTML required to do that. Web: That sounds very useful! Again, though, that’s not really HTML’s thing.
Author: I want to create my navigation bar in one place, then reuse it on every page. Web: Sorry, everything needs to be directly in the HTML! Well, yes, the browser can load CSS from other files… and JavaScript from other files… and SVG images from other files… just not HTML. Have you tried changing careers and learning JavaScript?
I understand at a technical level why these limitations exist. Working in web standards gave me an appreciation of the political difficulty of solving such problems even where solutions are possible. But none of that makes a new web author feel any better. Watching someone struggle to create a simple site makes clear that some very common authoring tasks are still disappointingly hard.